本文通过一个RDMA通信完整代码 RDMA-EXAMPLE展示RDMA 网络使用过程。
为适合初学者阅读,附录中简单介绍了RDMA 的架构与原理。
RDMA 编程详解
RDMA 通信过程
libibverbs库提供了用于使用RDMA的高级用户空间API3 4。使用这些API,程序运行过程如下:
1. 获取设备列表
首先必须检查得到本机可用的IB设备列表,列表中的每个设备都包含一个名字和GUID。
/* 1 获取设备列表 */
int num_devices;
struct ibv_device **dev_list = ibv_get_device_list(&num_devices);
if (!dev_list || !num_devices)
{
fprintf(stderr, "failed to get IB devices\n");
rc = 1;
goto main_exit;
}
2. 打开要请求的设备
遍历设备列表,通过设备的GUID或者名字选择并打开它,获取一个上下文:
/* 2 打开设备,获取设备上下文 */
struct ibv_device *ib_dev = dev_list[0];
res.ib_ctx = ibv_open_device(ib_dev);
if (!res.ib_ctx)
{
fprintf(stderr, "failed to open device \n");
rc = 1;
goto main_exit;
}
一般在这里需要释放设备列表占用的资源
/* 3 释放设备列表占用的资源 */
ibv_free_device_list(dev_list);
dev_list = NULL;
ib_dev = NULL;
3. 查询设备的工作能力
设备的工作能力能使用户了解已打开设备支持的特性和能力 ibv_port_attr。
/* 4 查询设备端口状态 */
if (ibv_query_port(res.ib_ctx, 1, &res.port_attr))
{
fprintf(stderr, "ibv_query_port on port failed\n");
rc = 1;
goto main_exit;
}
4. 分配保护域以及您的资源
保护域(PD)允许用户限制哪些组件只能相互交互。这个组件可以是AH、QP、MR、MW、和SRQ。
/* 5 创建PD(Protection Domain) */
res.pd = ibv_alloc_pd(res.ib_ctx);
if (!res.pd)
{
fprintf(stderr, "ibv_alloc_pd failed\n");
rc = 1;
goto main_exit;
}
5. 创建 CQ
一个CQ包含完成的工作请求(WR),每个WR将生成放置在CQ中的完成队列实体CQE,CQE将表明WR是否成功完成:
/* 6 创建CQ(Complete Queue) */
int cq_size = 10;
res.cq = ibv_create_cq(res.ib_ctx, cq_size, NULL, NULL, 0);
if (!res.cq)
{
fprintf(stderr, "failed to create CQ with %u entries\n", cq_size);
rc = 1;
goto main_exit;
}
6. 注册一个内存区域
在注册过程中,用户在特定保护域,设置内存权限并接收 lkey 和 rkey,稍后将使用这些秘钥来访问此内存缓冲区:
/* 7 注册MR(Memory Region) */
int size = MSG_SIZE;
res.buf = (char *)malloc(size);
if (!res.buf)
{
fprintf(stderr, "failed to malloc %Zu bytes to memory buffer\n", size);
rc = 1;
goto main_exit;
}
memset(res.buf, 0, size);
int mr_flags = IBV_ACCESS_LOCAL_WRITE | IBV_ACCESS_REMOTE_READ | IBV_ACCESS_REMOTE_WRITE;
res.mr = ibv_reg_mr(res.pd, res.buf, size, mr_flags);
if (!res.mr)
{
fprintf(stderr, "ibv_reg_mr failed with mr_flags=0x%x\n", mr_flags);
rc = 1;
goto main_exit;
}
fprintf(stdout, "MR was registered with addr=%p, lkey=0x%x, rkey=0x%x, flags=0x%x\n",
res.buf, res.mr->lkey, res.mr->rkey, mr_flags);
7. 创建 QP
创建 QP 还将创建关联的发送队列和接收队列:
/* 8 创建QP(Queue Pair) */
struct ibv_qp_init_attr qp_init_attr;
memset(&qp_init_attr, 0, sizeof(qp_init_attr));
qp_init_attr.qp_type = IBV_QPT_RC;
qp_init_attr.sq_sig_all = 1;
qp_init_attr.send_cq = res.cq;
qp_init_attr.recv_cq = res.cq;
qp_init_attr.cap.max_send_wr = 1;
qp_init_attr.cap.max_recv_wr = 1;
qp_init_attr.cap.max_send_sge = 1;
qp_init_attr.cap.max_recv_sge = 1;
res.qp = ibv_create_qp(res.pd, &qp_init_attr);
if (!res.qp)
{
fprintf(stderr, "failed to create QP\n");
rc = 1;
goto main_exit;
}
fprintf(stdout, "QP was created, QP number=0x%x\n", res.qp->qp_num);
8. 交换qp等控制信息
可以通过 Socket 或者 RDMA_CM API 来交换控制信息,这里演示的是使用 Socket 交换信息:
/* 9 交换控制信息 */
struct cm_con_data_t local_con_data; // 发送给远程主机的信息
struct cm_con_data_t remote_con_data; // 接收远程主机发送过来的信息
struct cm_con_data_t tmp_con_data;
local_con_data.addr = htonll((uintptr_t)res.buf);
local_con_data.rkey = htonl(res.mr->rkey);
local_con_data.qp_num = htonl(res.qp->qp_num);
local_con_data.lid = htons(res.port_attr.lid);
if (sock_sync_data(server_ip, sizeof(struct cm_con_data_t), (char *)&local_con_data, (char *)&tmp_con_data) < 0)
{
fprintf(stderr, "failed to exchange connection data between sides\n");
rc = 1;
goto main_exit;
}
remote_con_data.addr = ntohll(tmp_con_data.addr);
remote_con_data.rkey = ntohl(tmp_con_data.rkey);
remote_con_data.qp_num = ntohl(tmp_con_data.qp_num);
remote_con_data.lid = ntohs(tmp_con_data.lid);
/* save the remote side attributes, we will need it for the post SR */
res.remote_props = remote_con_data;
fprintf(stdout, "Remote address = 0x%" PRIx64 "\n", remote_con_data.addr);
fprintf(stdout, "Remote rkey = 0x%x\n", remote_con_data.rkey);
fprintf(stdout, "Remote QP number = 0x%x\n", remote_con_data.qp_num);
fprintf(stdout, "Remote LID = 0x%x\n", remote_con_data.lid);
其中 sock_sync_data 函数如下,先将本地的连接信息发送给远端,然后接受远端的 remote_data:
int sock_sync_data(int sock, int xfer_size, char *local_data, char *remote_data)
{
int rc;
int read_bytes = 0;
int total_read_bytes = 0;
rc = write(sock, local_data, xfer_size);
if (rc < xfer_size)
fprintf(stderr, "Failed writing data during sock_sync_data\n");
else
rc = 0;
while (!rc && total_read_bytes < xfer_size)
{
read_bytes = read(sock, remote_data, xfer_size);
if (read_bytes > 0)
total_read_bytes += read_bytes;
else
rc = read_bytes;
}
return rc;
}
接收任务初始化
将接收请求放入qp队列中:
struct ibv_recv_wr rr;
struct ibv_sge sge;
struct ibv_recv_wr *bad_wr;
int rc;
/* prepare the scatter/gather entry */
memset(&sge, 0, sizeof(sge));
sge.addr = (uintptr_t)res->buf;
sge.length = MSG_SIZE;
sge.lkey = res->mr->lkey;
/* prepare the receive work request */
memset(&rr, 0, sizeof(rr));
rr.next = NULL;
rr.wr_id = 0;
rr.sg_list = &sge;
rr.num_sge = 1;
/* post the Receive Request to the RQ */
rc = ibv_post_recv(res->qp, &rr, &bad_wr);
if (rc)
fprintf(stderr, "failed to post RR\n");
else
fprintf(stdout, "Receive Request was posted\n");
return rc;
9. 转换本地 QP 状态
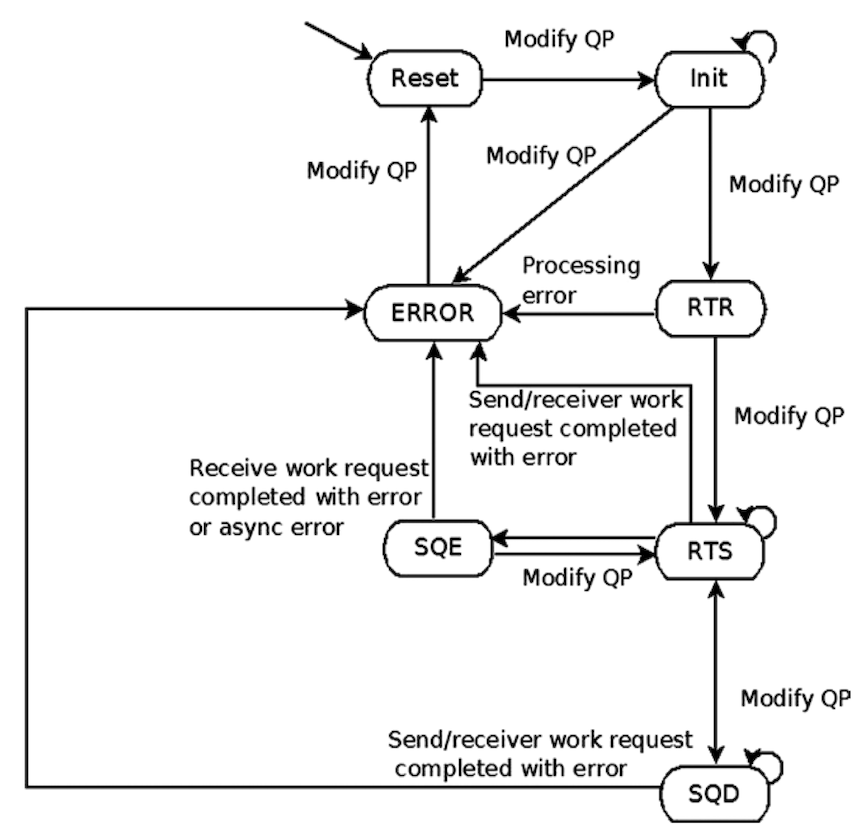
QP 有一个状态机,用于指定 QP 在各种状态下能够做什么:
- RESET:重置状态,QP 刚创建时即处于 RESET 状态,此时不能在 QP 中添加发送请求或接收请求,所有入站消息都被默默丢弃
- INIT:已初始化状态,此时不能添加发送请求,可以添加接收请求,但是请求不会被处理,所有入站消息都被默默丢弃。最好在QP处于这种状态时将接收请求加入到其中,再切换到 RTR 状态。这样可以避免发送消息的远程 QP 在需要使用接收请求时没有接收请求可用的情况发生。
- RTR:Ready To Receive 状态,此时不能添加发送请求,但是可以添加并且处理接收请求,所有入站信息都将得到处理。在这种状态下收到的第一条消息,将触发异步事件「通信已建立」
- RTS:Ready To Send 状态,此时可以添加和处理发送和接收请求,所有入站信息都将得到处理
- SQD:Send Queue Drained 状态,此时 QP 将完成所有已进入处理程序的发送请求的处理工作
- SQE:Send Queue Error 状态,传输类型为不可靠的 QP,当其发送队列出现错误时,RDMA 设备会自动将其切换到这个状态
- ERROR:错误状态,此时所有未处理的工作请求都被删除
状态:RESET -> INIT -> RTR -> RTS,要严格按照顺序进行转换,INIT之后就可以调用 ibv_post_recv 提交一个receive buffer了。
当 QP进入RTR(ready to receive)状态以后,便开始进行接收处理。RTR之后便可以转为RTS(ready to send),RTS状态下可以调用ibv_post_send
/* 转换QP状态 */
// RESET -> INIT
struct ibv_qp_attr attr;
int flags;
memset(&attr, 0, sizeof(attr));
attr.qp_state = IBV_QPS_INIT;
attr.port_num = 1; // IB 端口号
attr.pkey_index = 0;
attr.qp_access_flags = IBV_ACCESS_LOCAL_WRITE | IBV_ACCESS_REMOTE_READ | IBV_ACCESS_REMOTE_WRITE;
flags = IBV_QP_STATE | IBV_QP_PKEY_INDEX | IBV_QP_PORT | IBV_QP_ACCESS_FLAGS;
rc = ibv_modify_qp(res.qp, &attr, flags);
if (rc)
fprintf(stderr, "failed to modify QP state to INIT\n");
//INIT -> RTR(Ready To Receive)
memset(&attr, 0, sizeof(attr));
attr.qp_state = IBV_QPS_RTR;
attr.path_mtu = IBV_MTU_256;
attr.dest_qp_num = res.remote_props.qp_num;
attr.rq_psn = 0;
attr.max_dest_rd_atomic = 1;
attr.min_rnr_timer = 0x12;
attr.ah_attr.is_global = 0;
attr.ah_attr.dlid = res.remote_props.lid;
attr.ah_attr.sl = 0;
attr.ah_attr.src_path_bits = 0;
attr.ah_attr.port_num = 1;
flags = IBV_QP_STATE | IBV_QP_AV | IBV_QP_PATH_MTU | IBV_QP_DEST_QPN | IBV_QP_RQ_PSN | IBV_QP_MAX_DEST_RD_ATOMIC | IBV_QP_MIN_RNR_TIMER;
rc = ibv_modify_qp(res.qp, &attr, flags);
if (rc)
fprintf(stderr, "failed to modify QP state to RTR\n");
//RTR -> RTS(Ready To Send)
memset(&attr, 0, sizeof(attr));
attr.qp_state = IBV_QPS_RTS;
attr.timeout = 0x12;
attr.retry_cnt = 6;
attr.rnr_retry = 0;
attr.sq_psn = 0;
attr.max_rd_atomic = 1;
flags = IBV_QP_STATE | IBV_QP_TIMEOUT | IBV_QP_RETRY_CNT | IBV_QP_RNR_RETRY | IBV_QP_SQ_PSN | IBV_QP_MAX_QP_RD_ATOMIC;
rc = ibv_modify_qp(res.qp, &attr, flags);
if (rc)
fprintf(stderr, "failed to modify QP state to RTS\n");
/* sync to make sure that both sides are in states that they can connect to prevent packet loose */
if (sock_sync_data(res->sock, 1, "Q", &temp_char)) /* just send a dummy char back and forth */
{
fprintf(stderr, "sync error after QPs are were moved to RTS\n");
rc = 1;
}
10. 创建发送/接收任务
- 设置 ibv_send_wr(send work request)
- 该任务会被提交到QP中的SQ(Send Queue)中
- 发送任务有三种操作:Send,Read,Write
- Send操作需要对方执行相应的Receive操作
- Read/Write直接操作对方内存,对方无感知
- 把要发送的数据的内存地址,大小,密钥告诉HCA
- Read/Write还需要告诉HCA远程的内存地址和密钥
/* 创建发送任务ibv_send_wr */
struct ibv_send_wr sr;
struct ibv_sge sge;
struct ibv_send_wr *bad_wr = NULL;
int rc;
/* prepare the scatter/gather entry */
memset(&sge, 0, sizeof(sge));
sge.addr = (uintptr_t)res->buf;
sge.length = MSG_SIZE;
sge.lkey = res->mr->lkey;
/* prepare the send work request */
memset(&sr, 0, sizeof(sr));
sr.next = NULL;
sr.wr_id = 0;
sr.sg_list = &sge;
sr.num_sge = 1;
sr.opcode = opcode;
sr.send_flags = IBV_SEND_SIGNALED;
if (opcode != IBV_WR_SEND)
{
sr.wr.rdma.remote_addr = res->remote_props.addr;
sr.wr.rdma.rkey = res->remote_props.rkey;
}
10.1 提交发送/接收任务
- 发送
ibv_post_send - 接收
ibv_post_recv
rc = ibv_post_send(res->qp, &sr, &bad_wr);
if (rc)
fprintf(stderr, "failed to post SR\n");
return rc;
10.2 轮询任务完成信息
/* 13 轮询任务结果 */
struct ibv_wc wc;
int poll_result;
int rc = 0;
do
{
poll_result = ibv_poll_cq(res->cq, 1, &wc);
} while (poll_result == 0);
参考资料
- RDMA Aware Network Programming User Manual
- RDMA-Tutorial
- RDMA Mojo Blog
- https://houmin.cc/posts/454a90d3/
- InfiniBand体系架构和协议规范
- RDMA概述
附录
RDMA 传输模式
RDMA有两种基本操作,包括 Memory verbs 和 Messaging verbs:
-
Memory verbs:包括read、write和atomic操作,属于单边操作,只需要本端明确信息的源和目的地址,远端应用不必感知此次通信,数据的读或存都通过远端的DMA在RNIC与应用buffer之间完成,再由远端RNIC封装成消息返回到本端。
- RDMA Read:从远程主机读取部分内存。调用者指定远程虚拟地址,像本地内存地址一样用来拷贝。在执行 RDMA 读操作之前,远程主机必须提供适当的权限来访问它的内存。一旦权限设置完成, RDMA 读操作就可以在对远程主机没有任何通知的条件下执行。不管是 RDMA 读还是 RDMA 写,远程主机都不会意识到操作正在执行 (除了权限和相关资源的准备操作)。
- RDMA Write:与 RDMA Read 类似,只是数据写到远端主机中。RDMA写操作在执行时不通知远程主机。然而带即时数的RDMA写操作会将即时数通知给远程主机。
- RDMA Atomic:包括原子取、原子加、原子比较和原子交换,属于RDMA原子操作的扩展。
-
Messaging verbs:包括send和receive操作,属于双边操作,即必须要远端的应用感知参与才能完成收发。
- RDMA Send:发送操作允许你把数据发送到远程 QP 的接收队列里。接收端必须已经事先注册好了用来接收数据的缓冲区。发送者无法控制数据在远程主机中的放置位置。可选择是否使用即时数,一个4位的即时数可以和数据缓冲一起被传送。这个即时数发送到接收端是作为接收的通知,不包含在数据缓冲之中。
- RDMA Receive:这是与发送操作相对应的操作。接收主机被告知接收到数据缓冲,还可能附带一个即时数。接收端应用程序负责接收缓冲区的维护和发布。
RDMA Consortium 和 IBTA 主导了RDMA,RDMAC是IETF的一个补充,它主要定义的是iWRAP和iSER,IBTA是infiniband的全部标准制定者,并补充了RoCE v1 v2的标准化。应用和RNIC之间的传输接口层(software transport interface)被称为Verbs。IBTA解释了RDMA传输过程中应具备的特性行为,而并没有规定Verbs的具体接口和数据结构原型。这部分工作由另一个组织OFA(Open Fabric Alliance)来完成,OFA提供了RDMA传输的一系列Verbs API。OFA开发出了OFED(Open Fabric Enterprise Distribution)协议栈,支持多种RDMA传输层协议。
OFED中除了提供向下与RNIC基本的队列消息服务,向上还提供了ULP**(Upper Layer Protocols**),通过ULPs**,上层应用不需要直接与Verbs API对接,而是借助于ULP与应用对接,常见的应用不需要做修改,就可以跑在RDMA**传输层上。
RDMA 单边操作
单边操作传输方式是RDMA与传统网络传输的最大不同,提供直接访问远程的虚拟地址,无须远程应用的参与,这种方式适用于批量数据传输。
READ和WRITE是单边操作,只需要本端明确信息的源和目的地址,远端应用不必感知此次通信,数据的读或写都通过RDMA在RNIC与应用Buffer之间完成,再由远端RNIC封装成消息返回到本端。
RDMA Read
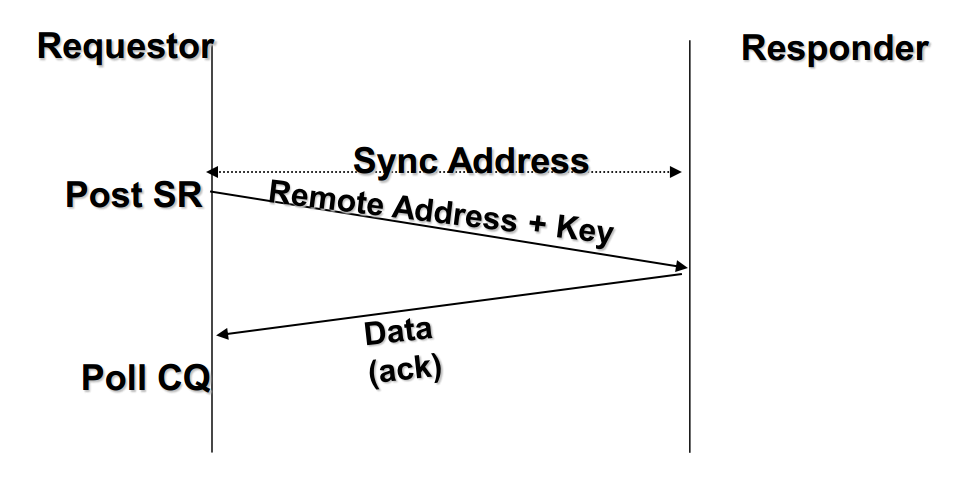
对于单边操作,以存储网络环境下的存储为例,数据的流程如下:
- 首先A、B建立连接,QP已经创建并且初始化。
- 数据被存档在 B 的 buffer地址 VB,注意VB应该提前注册到B的RNIC (并且它是一个Memory Region) ,并拿到返回的local key,相当于RDMA操作这块buffer的权限。
- B 把数据地址 VB,key封装到专用的报文传送到A,这相当于B把数据buffer的操作权交给了A。同时B在它的WQ中注册进一个WR,以用于接收数据传输的A返回的状态。
- A 在收到 B 的送过来的数据 VB 和 R_key 后,RNIC 会把它们连同自身存储地址 VA 到封装 RDMA READ 请求,将这个消息请求发送给B,这个过程A、B两端不需要任何软件参与,就可以将 B 的数据存储到 B 的 VA虚拟地址。
- B在存储完成后,会向A返回整个数据传输的状态信息。
RDMA Write
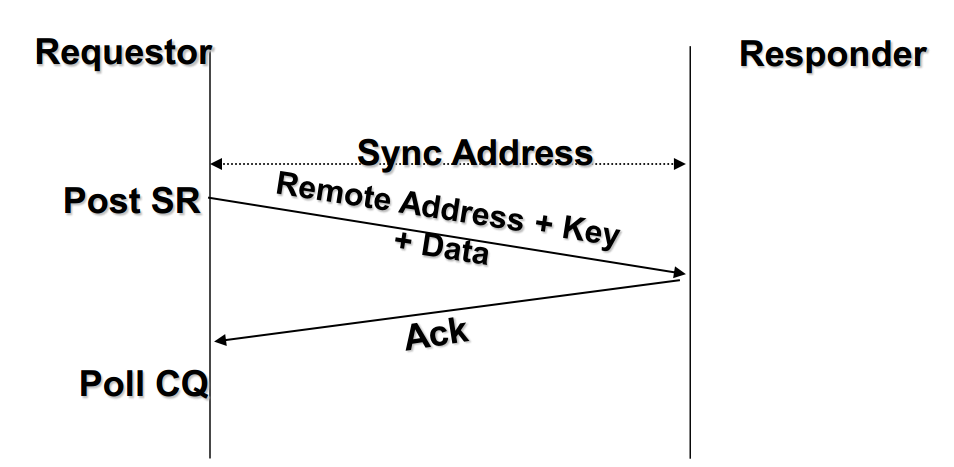
对于单边操作,以存储网络环境下的存储为例,数据的流程如下:
- 首先A、B建立连接,QP已经创建并且初始化。
- 数据 remote目标存储buffer地址VB,注意VB应该提前注册到B的RNIC(并且它是一个Memory Region),并拿到返回的local key,相当于RDMA操作这块buffer的权限。
- B把数据地址VB,key封装到专用的报文传送到A,这相当于B把数据buffer的操作权交给了A。同时B在它的WQ中注册进一个WR,以用于接收数据传输的A返回的状态。
- A在收到B的送过来的数据VB和R_key后,RNIC会把它们连同自身发送地址VA到封装RDMA WRITE请求,这个过程A、B两端不需要任何软件参与,就可以将A的数据发送到B的VB虚拟地址。
- A在发送数据完成后,会向B返回整个数据传输的状态信息。
RDMA 双边操作
双边操作与传统网络的底层buffer pool类似,收发双方的参与过程并无差别,区别在零拷贝、kernel bypass,实际上传统网络中一些高级的网络SOC 已经实现类似功能。对于RDMA,这是一种复杂的消息传输模式,多用于传输短的控制消息。
RDMA 中 SEND/RECEIVE 是双边操作,即必须要远端的应用感知参与才能完成收发。在实际中,SEND/RECEIVE多用于连接控制类报文,而数据报文多是通过READ/WRITE来完成的。对于双边操作为例,主机 A 向主机 B 发送数据的流程如下:
- 首先,A 和 B 都要创建并初始化好各自的QP、CQ,并且为 RDMA 注册了 Memory Region,A 想发送数据给 B
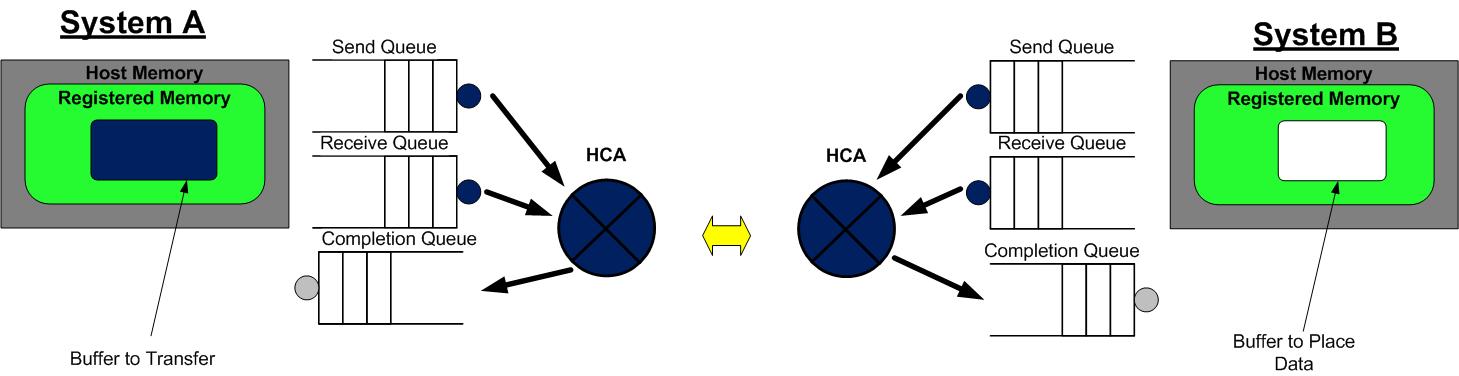
- A 和 B 分别向自己的WQ中注册WQE,对于A,WQ=SQ,WQE描述指向一个等到被发送的数据;对于B,WQ=RQ,WQE描述指向一块用于存储数据的Buffer
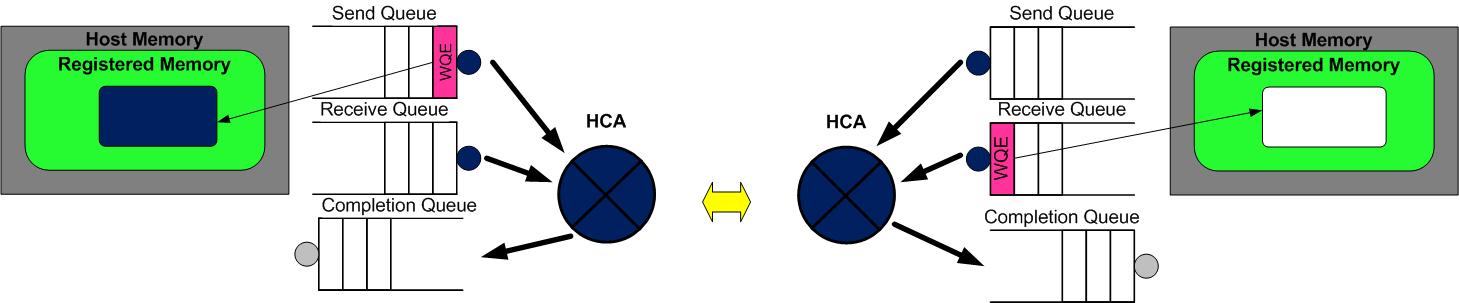
- A 的 HCA 作为硬件总是从 SQ 中取出 WQE,解析到这是一个SEND消息,将数据直接从 A 的 Buffer 中发给 B。数据流到达B的RNIC后,B 的 HCA 将会从 RQ 中取出 WQE,并把数据直接存储到 WQE 指向的存储位置。
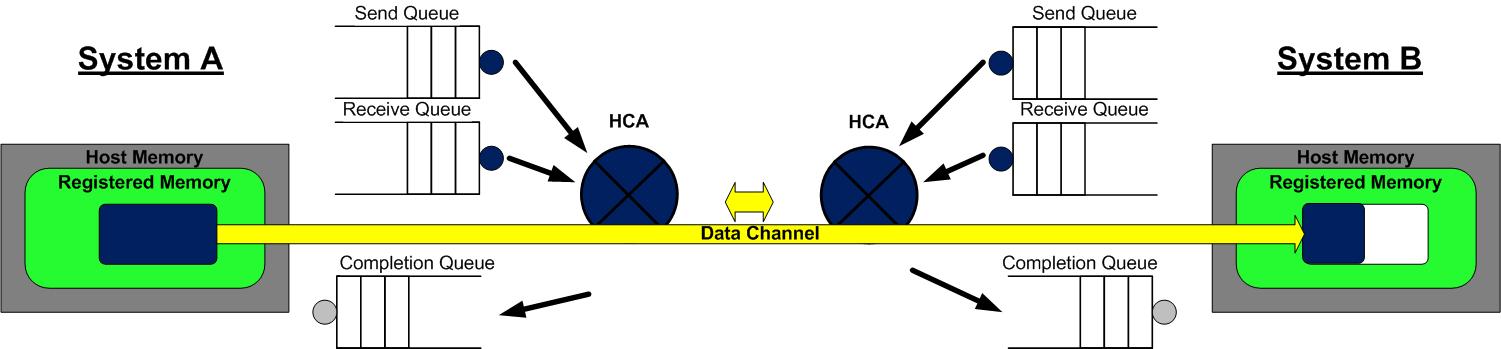
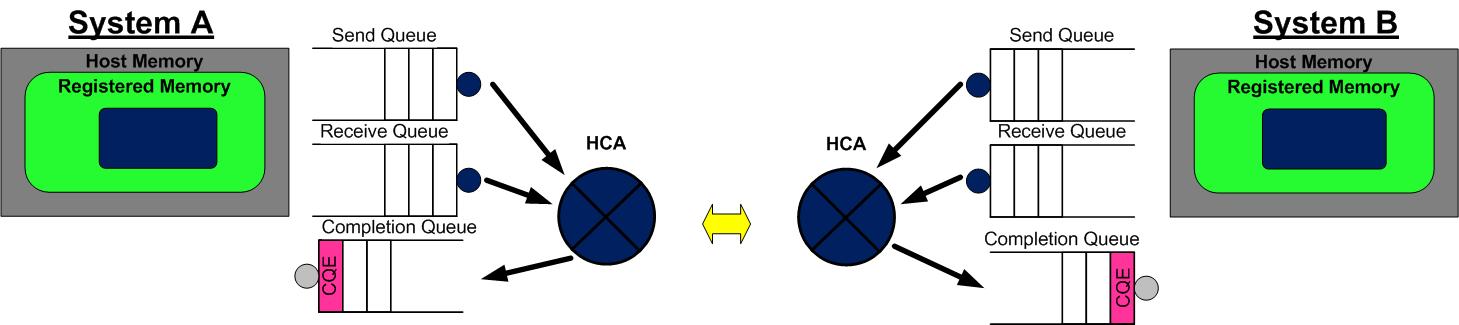
- AB 通信完成后,A的CQ中会产生一个完成消息 CQE 表示发送完成。与此同时,B 的 CQ 中也会产生一个完成消息表示接收完成。每个WQ中WQE的处理完成都会产生一个CQE。 即使传输发生错误,也会产生 CQE,CQE 中会有字段表明传输的状态。
Send Request
SR 定义了数据的发送量、从哪里、发送方式、是否通过 RDMA、到哪里。
结构 ibv_send_wr 用来描述 SR。
struct ibv_send_wr {
uint64_t wr_id;
struct ibv_send_wr *next;
struct ibv_sge *sg_list;
int num_sge;
enum ibv_wr_opcode opcode;
unsigned int send_flags;
/* When opcode is *_WITH_IMM: Immediate data in network byte order.
* When opcode is *_INV: Stores the rkey to invalidate
*/
union {
__be32 imm_data;
uint32_t invalidate_rkey;
};
union {
struct {
uint64_t remote_addr;
uint32_t rkey;
} rdma;
struct {
uint64_t remote_addr;
uint64_t compare_add;
uint64_t swap;
uint32_t rkey;
} atomic;
struct {
struct ibv_ah *ah;
uint32_t remote_qpn;
uint32_t remote_qkey;
} ud;
} wr;
union {
struct {
uint32_t remote_srqn;
} xrc;
} qp_type;
union {
struct {
struct ibv_mw *mw;
uint32_t rkey;
struct ibv_mw_bind_info bind_info;
} bind_mw;
struct {
void *hdr;
uint16_t hdr_sz;
uint16_t mss;
} tso;
};
};
Receive Request
RR 定义用来放置通过 RDMA 操作接收到的数据的缓冲区。如没有定义缓冲区,并且有个传输者尝试执行一个发送操作或者一个带即时数的 RDMA 写操作,那么接收者将会发出接收未就绪的错误(RNR)。
结构 ibv_recv_wr 用来描述 RR。
struct ibv_recv_wr {
uint64_t wr_id;
struct ibv_recv_wr *next;
struct ibv_sge *sg_list;
int num_sge;
};
Queue Pairs
RDMA提供了基于消息队列的点对点通信,每个应用都可以直接获取自己的消息,无需操作系统和协议栈的介入。消息服务建立在通信双方本端和远端应用之间创建的Channel-IO连接之上。当应用需要通信时,就会创建一条Channel连接,每条Channel的首尾端点是两对Queue Pairs(QP)。每对QP由Send Queue(SQ)和Receive Queue(RQ)构成,这些队列中管理着各种类型的消息。QP会被映射到应用的虚拟地址空间,使得应用直接通过它访问RNIC网卡。除了QP描述的两种基本队列之外,RDMA还提供一种队列Complete Queue(CQ),CQ用来知会用户WQ上的消息已经被处理完。
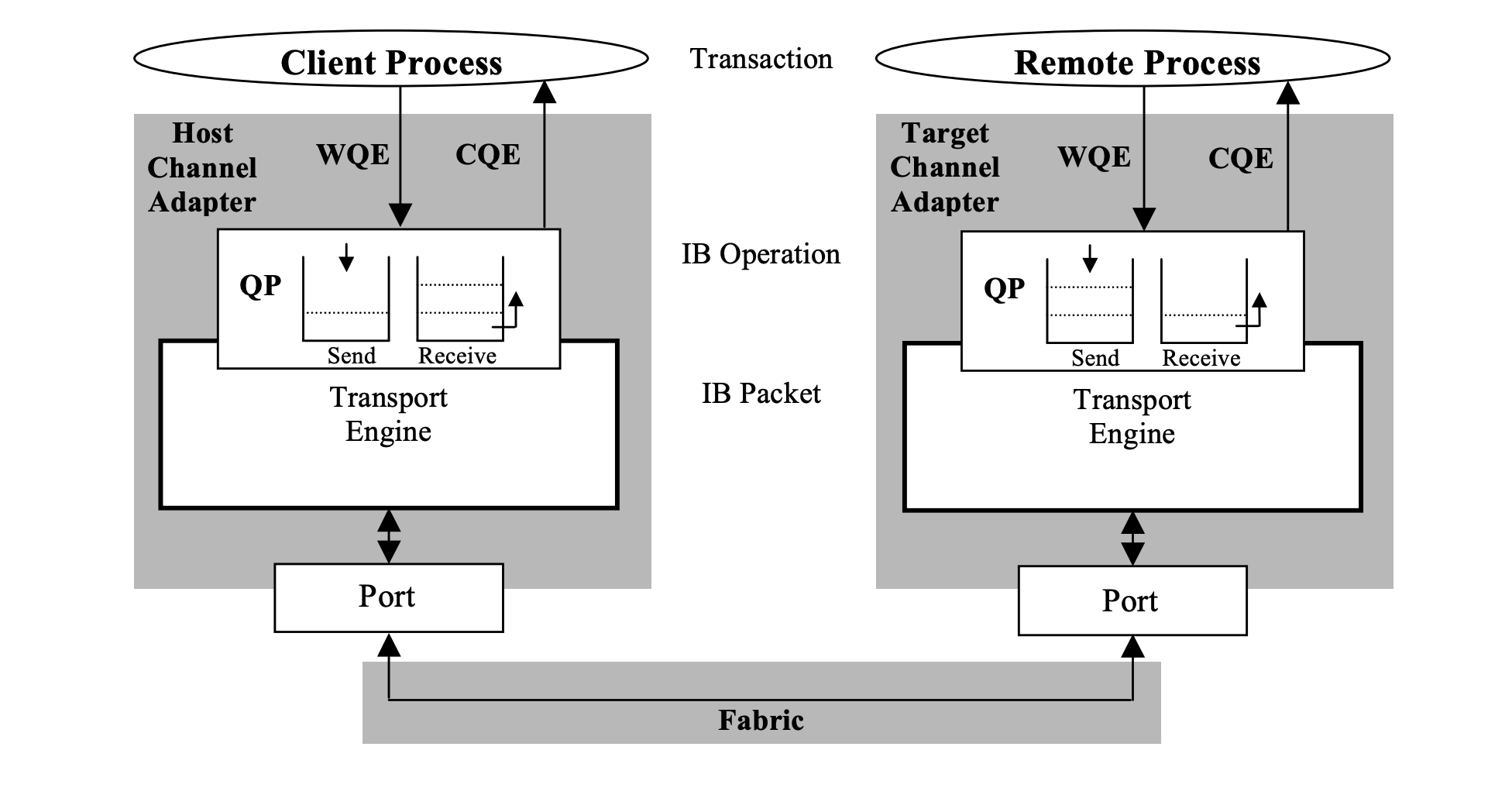
RDMA提供了一套软件传输接口,方便用户创建传输请求Work Request(WR),WR中描述了应用希望传输到Channel对端的消息内容,WR 通知QP中的某个队列Work Queue(WQ)。在 WQ 中,用户的 WR 被转化为Work Queue Element(WQE)的格式,等待RNIC的异步调度解析,并从WQE指向的Buffer中拿到真正的消息发送到 Channel 对端。
struct ibv_qp {
struct ibv_context *context;
void *qp_context;
struct ibv_pd *pd;
struct ibv_cq *send_cq;
struct ibv_cq *recv_cq;
struct ibv_srq *srq;
uint32_t handle;
uint32_t qp_num;
enum ibv_qp_state state;
enum ibv_qp_type qp_type;
pthread_mutex_t mutex;
pthread_cond_t cond;
uint32_t events_completed;
};
Completion Queue
发送到 SQ 和 RQ 的工作请求都被视为未完成,工作请求未完成期间,它指向的内存缓冲区的内容是不确定的。
CQ 包含了发送到工作队列(WQ)中已完成的工作请求(WR)。每次完成表示一个特定的 WR 执行完毕(包括成功完成的 WR 和不成功完成的 WR)。完成队列是一个用来告知应用程序已经结束的工作请求的信息(状态、操作码、大小、来源)的机制。
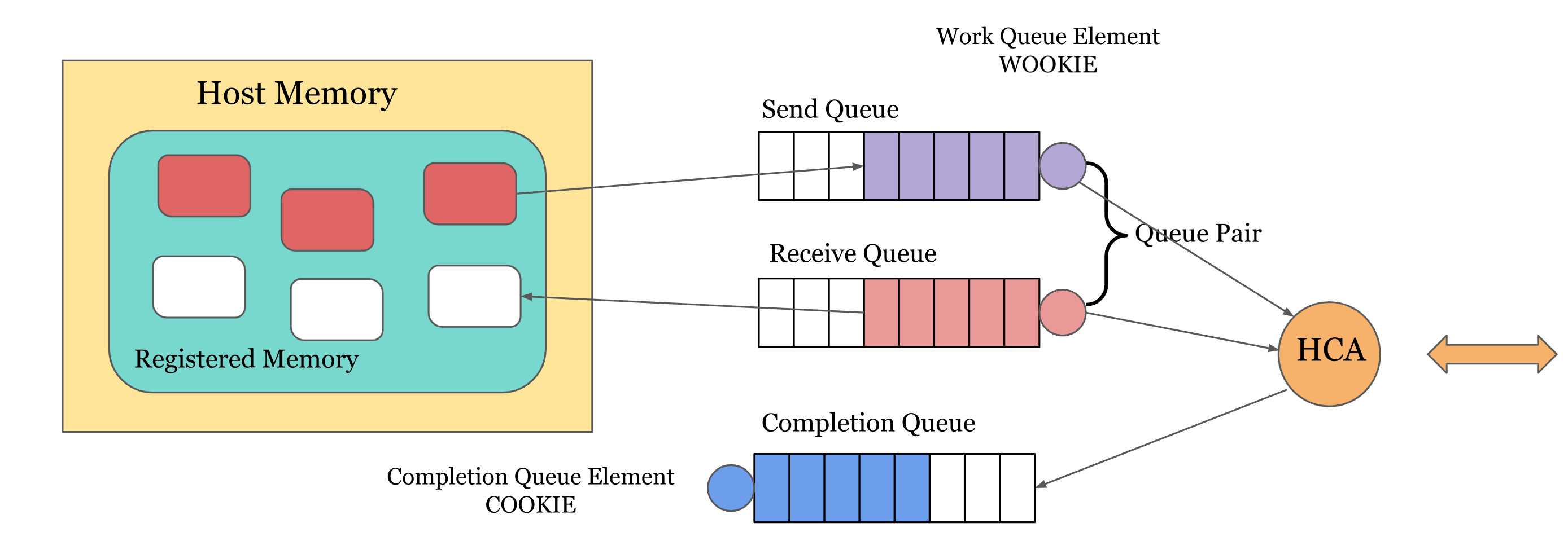
CQ有n个完成队列实体(CQE),CQE 的数量在CQ创建时指定。当一个CQE被 轮询 到,它就从CQ中被删除。CQ是一个CQE的 FIFO 队列。CQ能服务于发送队列、接收队列或者同时服务于这两种队列。多个不同QP中的工作请求(WQ)可联系到同一个CQ上。
结构 ibv_cq 用来描述CQ。
struct ibv_cq {
struct ibv_context *context;
struct ibv_comp_channel *channel;
void *cq_context;
uint32_t handle;
int cqe;
pthread_mutex_t mutex;
pthread_cond_t cond;
uint32_t comp_events_completed;
uint32_t async_events_completed;
};
Memory Registration
RDMA 设备访问的每一个内存缓冲区都必须注册,在注册过程中,将对内存缓冲区执行如下操作:
- 将连续的内存缓冲区分成内存页,将这些内存空间提供给网络适配器作为虚拟的连续缓冲区,缓冲区使用虚拟地址
- 将虚拟内存映射到物理内存,注册进程将虚拟地址与物理地址的映射表写入网络适配器。
- 检查内存页权限,确保它们支持为 MR(Memory Region) 发出请求的权限
- 锁定内存页权限,以防它们被换出,确保虚拟内存到物理内存的映射不变
注册成功后,内存有两个键:
- 本地键
lkey:供本地工作请求用来访问内存的 key - 远程键
rkey:供远程机器通过 RDMA 访问内存的 key
在工作请求中,将使用这些 key 来访问内存缓冲区,同一内存缓冲区可以被多次注册(甚至设置不同的操作权限),并且每次注册都会生成不同的 key。
结构 ibv_mr 用来描述内存注册。
struct ibv_mr {
struct ibv_context *context;
struct ibv_pd *pd;
void *addr;
size_t length;
uint32_t handle;
uint32_t lkey;
uint32_t rkey;
};
Memory Window
启用远程内存访问的方式有以下两种:
- 注册允许远程内存访问的内存缓冲区
- 注册内存区并将其绑定到内存窗口
这两种方式都将创建一个 rkey,可用来访问制定的内存。然而,如果想要这个rkey 无效,以禁止访问该内存时。采用注销内存区的方式实现起来比较繁琐。而使用内存窗口,并根据需要进行绑定和解除绑定,对于启动和禁用远端内存访问简单灵活得多。
内存窗口作用于以下场景:
- 动态地授予和回收已注册缓冲区的远程访问权限,这种方式相较于将缓冲区取消注册、再注册或者重注册,有更低的性能损耗代价。
- 想为不同的远程代理授予不同的远程访问方式,或者在一个已注册的缓冲区中不同范围授予哪些权限。
内存窗口和内存注册之间的关联操作叫做绑定。不同的MW可以做用于同一个MR,即使有不同的访问权限。
Address Vector
地址向量用来描述本地节点到远程节点的路由。在QP的每个UC/RC中,都有一个地址向量存在于QP的上下文中。在UD的QP中,每个提交的发送请求(SR)中都应该定义地址向量。
结构 ibv_ah用来描述地址向量。
Global Routing Header(GRH)
GRH用于子网之间的路由。当用到RoCE时,GRH用于子网内部的路由,并且是强制使用的,强制使用GRH是为了保证应用程序即支持IB又支持RoCE。当全局路由用在给予UD的QP时,在接受缓冲区的前40字节会包含有一个GRH。这个区域专门存储全局路由信息,为了回应接收到的数据包,会产生一个合适的地址向量。如果向量用在UD中,接收请求RR应该总是有额外的40字节用来GRH。
结构 ibv_grh 用来描述GRH。
Protection Domain
保护域是一种集合,它的内部元素只能与集合内部的其它元素相互作用。这些元素可以是AH、QP、MR、和SRQ。保护域用于QP与内存注册和内存窗口相关联,这是一种授权和管理网络适配器对主机系统内存的访问。PD也用于将给予不可靠数据报(UD)的QP关联到地址处理(AH),这是一种对UD目的端的访问控制。
struct ibv_pd {
struct ibv_context *context;
uint32_t handle;
};
评论