RDMA 编程实践
本文介绍了RDMA编程基础知识,让你从代码角度理解IB RDMA工作原理。
背景信息
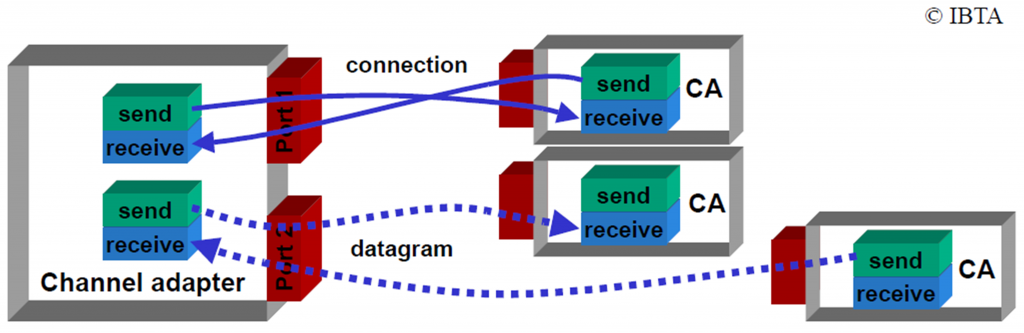
通道适配器(Channel Adapter, CA)
通道适配器是Infiniband网络中的端节点,相当于以太网网络接口卡(NIC),但具有更多关于Infiniband和RDMA的功能1。
这些Infiniband网络接口卡被称为**(主机)通道适配器(Host Channel Adapter, HCA)**2。
队列对(QP)
HCAs使用工作队列相互通信。队列分为三种类型:(1) 发送队列(SQ),(2) 接收队列(RQ),和(3)完成队列(CQ)。
SQ和RQ总是成组管理,作为一个队列对(QP)。
我们可以通过向工作队列中生成一个工作队列条目(WRE)来发布工作请求(WR),比如:
- (1)将发送工作请求发布到SQ中以向远程节点发送一些数据
- (2)将接收工作请求发布到RQ中以从远程节点接收数据等。发布的工作请求直接由硬件(HCA)处理3 4。
- 一旦请求完成,硬件将在完成队列(CQ)中发布一个工作完成(WC)。编程接口提供了灵活性,可以为SQ和RQ指定不同的完成队列,或者使用一个CQ用于整个QP。
简而言之,编写RDMA程序大致如下:生成一个QP和一个CQ(以及其他此操作所需的数据结构,稍后将介绍),将QP连接到远程节点,并生成工作请求(WR)并将其发布到QP。 然后HCA将您的指令传递给连接的对等节点。
libibverbs APIs
libibverbs库提供了用于使用Infiniband HCAs的高级用户空间API3 4。使用这些API,程序运行过程如下:
- 创建一个Infiniband上下文(
struct ibv_context* ibv_open_device())。 - 创建一个保护域(
struct ibv_pd* ibv_alloc_pd())。 - 创建一个完成队列(
struct ibv_cq* ibv_create_cq())。 - 创建一个队列对(
struct ibv_qp* ibv_create_qp())。 - 交换标识符信息以建立连接:服务器和客户端建立TCP连接,并交换其本地ID和QP编号。
- 改变队列对的状态(
ibv_modify_qp()):将队列对的状态从RESET更改为INIT,RTR(准备接收)和最终RTS(准备发送)5。 - 注册一个内存区域(
ibv_reg_mr())。 - 交换内存区域信息以处理操作:服务器和客户端建立TCP连接,交换内存区域信息:地址、内存大小、lkey, rkey。
- 执行数据通信。
在3,[4]以及许多示例代码中,6:内存区域注册被说明为初始化的一部分(在第2~6步之间的某个地方)。然而,延迟注册没有问题,内存区域可以在提交工作请求之前的任何时间动态注册和注销(在第6步之后)。
具体来说,我想将程序流分为两组:第1~6步作为初始化阶段,第7~9步作为运行时阶段。我们将在第7步中进一步讨论这一点。
请注意,4将相关的函数列出并分组得很好。我只展示这些函数调用的顺序。
1. 创建Infiniband上下文
打开HCA并生成用户空间设备上下文。
struct ibv_context* createContext(const std::string& device_name) {
/*无法直接通过设备名打开设备,首先需要获取设备列表。*/
struct ibv_context* context = nullptr;
int num_devices;
struct ibv_device** device_list = ibv_get_device_list(&num_devices);
for (int i = 0; i < num_devices; i++){
/*匹配设备名,打开设备并返回。*/
if (device_name.compare(ibv_get_device_name(device_list[i])) == 0) {
context = ibv_open_device(device_list[i]);
break;
}
}
/*释放设备列表是重要的,否则会造成内存泄漏。*/
ibv_free_device_list(device_list);
if (context == nullptr) {
std::cerr << "无法找到设备 " << device_name << std::endl;
}
return context;
}
2. 创建保护域
实际上创建一个保护域,保护资源免受远程的任意访问。可以注册到保护域的组件有:
- 内存区域(MRs)
- 内存窗口(MWs)
- 队列对(QPs)
- 共享接收队列(SRQs)
- 地址句柄(AH)1。
需要注意的是完成队列(CQs)不在保护域中4。
例如,注册内存区域需要一个指向保护域的指针,表示该内存区域将被注册到保护域中。
struct ibv_mr *ibv_reg_mr(struct ibv_pd *pd, ...); [手册页]
如前所述,创建保护域后,并不一定需要立即注册内存区域。由于队列对也会注册到保护域中,创建保护域是一个早期的初始化步骤。
struct ibv_context* context = createContext(/*设备名*/);
struct ibv_pd* protection_domain = ibv_alloc_pd(context);
3. 创建完成队列
这是创建队列对的前提步骤,类似于第2步。
struct ibv_context* context = createContext(/*设备名*/);
int cq_size = 0x10;
struct ibv_cq* completion_queue = ibv_create_cq(context,cq_size,nullptr,nullptr,0);
ibv_create_cq的函数签名是: struct ibv_cq *ibv_create_cq(struct ibv_context *context, int cqe, void *cq_context, struct ibv_comp_channel *channel, int comp_vector);。[手册页]
我看到的所有示例都将cq_context和channel都传递为nullptr并且都正常工作,所以我不明白它们到底是做什么的。
4. 创建队列对
现在我们可以创建一个队列对了。
int ib_port;
ib_port is the local InfiniBand port number on which the connection between the queue pairs will be established. It is an integer value.
destination_qp_number
ib_port是此队列对在主机上使用的端口号。您可以使用ibstat轻松查看设备支持的端口数量及其编号:
$ ibstat
CA 'mlx5_0'
CA类型:MT4115
端口数量:1
固件版本:12.23.1020
硬件版本:0
节点GUID:/*省略*/
系统镜像GUID:/*省略*/
端口1:
状态:活动的
物理状态:链路正常
速率:56
基本LID:13
LMC:0
SM LID:9
能力掩码:/*省略*/
端口GUID:/*省略*/
链路层:InfiniBand
如果您想使用
ibstat命令,请安装infiniband-diags。
我的CA有一个端口,端口号为1。您可以在启动程序时手动传递此信息。
destination_qp_number和destination_local_id
为了使队列对连接到另一个队列对并准备接收,它必须知道有关对等QP的信息:destination_qp_number和destination_local_id。
destination_local_id:它在HCA所分配的子网中作为本地标识符起作用。子网管理器将其分配给每个端口,并且在其子网中是唯一的。对于子网上的通信,我们可以使用GID(全局ID),但本文不涉及此内容。要查找本地ID,可以使用以下函数。
uint16_t getLocalId(struct ibv_context* context, int ib_port) {
ibv_port_attr port_attr;
ibv_query_port(context, ib_port, &port_attr);
return port_attr.lid;
}
destination_qp_number:队列对至少已创建,因此唯一标识符已分配。
uint32_t getQueuePairNumber(struct ibv_qp* qp) {
return qp->qp_num;
}
请注意,这些函数返回的是其本地信息,而不是目标信息(对方节点的信息)。这意味着这些函数必须在每一端调用,并交换信息以了解彼此的目标信息。
**出于此目的,我参考的所有示例都使用TCP套接字。**在处理RDMA操作之前,服务器和客户端建立TCP连接,并交换其本地ID和QP编号。这就是为什么第5步包括交换标识符信息的原因。
TCP连接还在第8步中使用,以通知对方关于其内存区域。
在调用changeQueuePairStateToRTR()之后,队列对将无法通过发布接收工作请求来接收数据。如果要使其能够发送数据,则需要进一步将状态更改为RTS。
bool changeQueuePairStateToRTS(struct ibv_qp* queue_pair) {
struct ibv_qp_attr rts_attr;
memset(&rts_attr, 0, sizeof(rts_attr));
rts_attr.qp_state = ibv_qp_state::IBV_QPS_RTS;
rts_attr.timeout = 0x12;
rts_attr.retry_cnt = 7;
rts_attr.rnr_retry = 7;
rts_attr.sq_psn = 0;
rts_attr.max_rd_atomic = 1;
return ibv_modify_qp(queue_pair, &init_attr, IBV_QP_STATE | IBV_QP_TIMEOUT | IBV_QP_RETRY_CNT | IBV_QP_RNR_RETRY | IBV_QP_SQ_PSN | IBV_QP_MAX_QP_RD_ATOMIC) == 0 ? true : false;
}
由于对等信息已经存储在RTR步骤中,将状态更改为RTS不需要任何进一步的对等信息。
7. 注册内存区域
到第6步为止,这是一个初始化阶段。在第6步之后,队列对可以相互通信。发布的工作请求将转发到对方节点,其HCA将消耗它。当然,由于没有注册内存区域,这将被拒绝,因为工作请求无法从对等节点的任何空间中读取或写入任何内容。
换句话说,在对等节点发布工作请求之前注册内存区域是可以的。
在进一步讨论之前,让我们深入了解Infiniband支持的操作类型(参见[1]中的2.1节):
- 发送/立即发送:[需要RTS状态]将数据发送到远程QP的接收队列。
- 接收:[需要RTR/RTS状态]是发送操作的对应操作;主机在接收到数据缓冲区时会收到通知。
- RDMA读取:[需要RTS状态]从远程内存中读取数据。远程端不知道此操作正在进行。
- RDMA写入/立即写入:[需要RTS状态]将数据写入远程内存。远程端不知道此操作正在进行。
- 原子获取并交换/原子比较并交换:参见[1]中的2.1.4节
这些序列图[4]如下图所示:
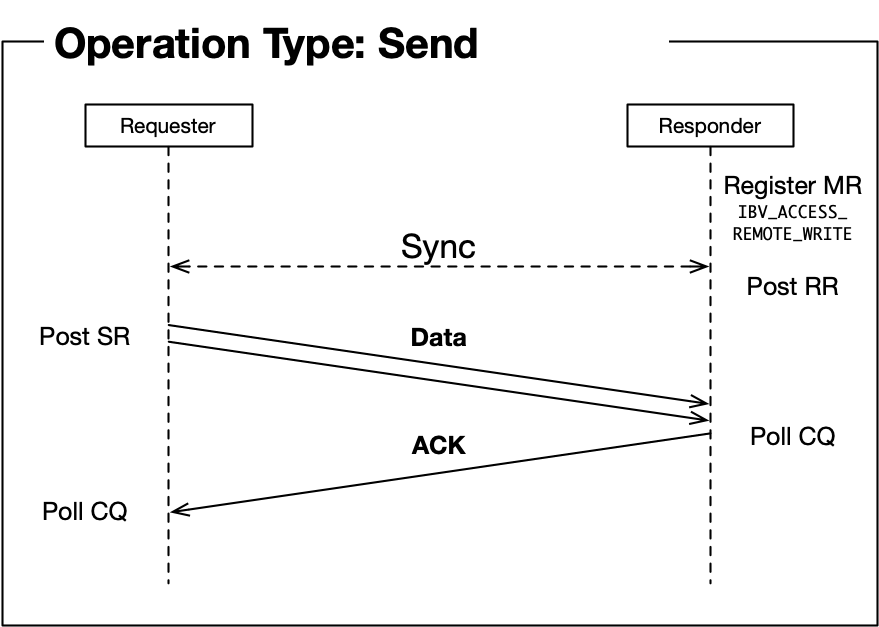
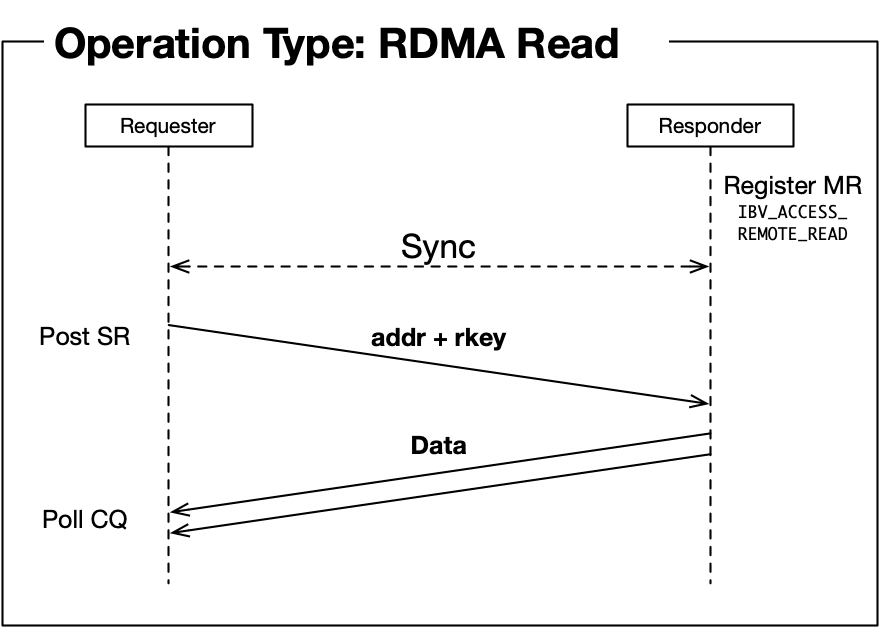
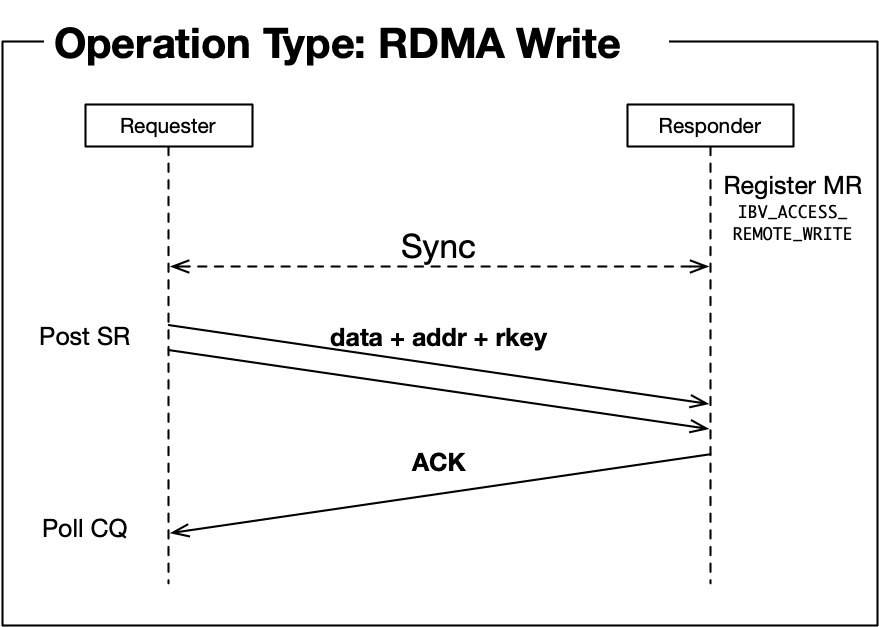
内存区域注册大多在"初始化阶段"由RDMA操作。不同于接收操作,远程端主动提交接收工作请求,因此在提交接收工作请求之前注册内存区域。RDMA读取和写入可以在远程节点上不进行任何操作的情况下完成,因此需要预先注册内存区域, 。
在操作中,初始化没有注册内存区域的队列是没有问题的。若不注册内存,但HCA无法从远程节点的内存中读取或写入数据。
要注册内存区域,可以使用ibv_reg_mr()函数。
struct ibv_mr* registerMemoryRegion(struct ibv_pd* pd, void* buffer, size_t size) {
return ibv_reg_mr(pd, buffer, size, IBV_ACCESS_LOCAL_WRITE | IBV_ACCESS_REMOTE_READ | IBV_ACCESS_REMOTE_WRITE);
}
注意,我们可以在内存区域中指定远程访问的范围。有五个标志位可供选择(详见手册页):
IBV_ACCESS_LOCAL_WRITE:启用本地写访问IBV_ACCESS_REMOTE_WRITE:启用远程写访问IBV_ACCESS_REMOTE_READ:启用远程读访问IBV_ACCESS_REMOTE_ATOMIC:启用远程原子操作访问IBV_ACCESS_MW_BIND:启用内存窗口绑定
如果设置了IBV_ACCESS_REMOTE_WRITE或IBV_ACCESS_REMOTE_ATOMIC,则还必须设置IBV_ACCESS_LOCAL_WRITE。
8. 交换内存区域信息以处理操作和9. 执行数据通信
内存区域是通信所需的数据,还必须通过TCP通道发送。
下面是通过调用ibv_reg_mr()返回的已注册内存区域的数据结构:
struct ibv_mr {
struct ibv_context *context;
struct ibv_pd *pd;
void *addr;
size_t length;
uint32_t handle;
uint32_t lkey;
uint32_t rkey;
};
我们实际需要进行数据传输的是:
- 地址
- 长度
- lkey(本地键)
- rkey(远程键)
其他数据不是必需的,但简单地将整个数据作为字节流发送就足够了。
有了内存区域信息,您可以使用ibv_post_send()和ibv_post_recv()在两个设备之间使用RDMA。
Send/Recv
发送和接收是一对操作,它们互相使用,才能正常运行。
bool postReceiveRequest(const std::vector<struct ibv_mr*>& sge) {
struct ibv_recv_wr receive_wr, *bad_wr = nullptr;
memset(&receive_wr, 0, sizeof(receive_wr));
// RDMA支持scatter-gather I/O。
//对于RECV操作,它的作用就像scatter;接收到的数据将分散到几个已注册的MR中。
struct ibv_sge* receive_sge = calloc(sizeof(struct ibv_sge), sge.size());
for (int i = 0; i < sge.size(); i++) {
receive_sge[i].addr = (uintptr_t) sge[i].addr;
receive_sge[i].length = sge[i].length;
receive_sge[i].lkey = sge[i].lkey;
}
receive_wr.sg_list = receive_sge;
receive_wr.num_sge = sge.size();
//将用于标识。当请求失败时,ibv_poll_cq()会返回一个包含指定wr_id的工作完成(struct ibv_wc)。
//如果wr_id是100,我们可以很容易地查明此RECV请求失败了。
receive_wr.wr_id = 100;
//您可以链接几个接收请求以减少软件占用空间,从而提高延迟。
receive_wr.next = nullptr;
// 如果发布失败,则将坏WR中链接的WR的地址存储在bad_wr中。
auto result = ibv_post_recv(queue_pair_, &receive_wr, &bad_wr);
free(receive_sge);
return result == 0 ? true : false;
}
bool postSendRequest(const std::vector<struct ibv_mr*>& sge) {
struct ibv_send_wr send_wr, *bad_wr = nullptr;
memset(&send_wr, 0, sizeof(send_wr));
struct ibv_sge* send_sge = calloc(sizeof(struct ibv_sge), sge.size());
for (int i = 0; i < sge.size(); i++) {
send_sge[i].addr = (uintptr_t) sge[i].addr;
send_sge[i].length = sge[i].length;
send_sge[i].lkey = sge[i].lkey;
}
send_wr.sg_list = send_sge;
send_wr.num_sge = sge.size();
send_wr.wr_id = 200;
//通过ibv_send_wr将所有发布到发送队列(SQ)的WR都发布。
//您应该指定操作码,以便指定要执行的操作。
send_wr.opcode = IBV_WR_SEND;
//使用IBV_SEND_SIGNALED标志,硬件将在连接到发送队列的完成队列中创建工作完成(wc)条目。
//您可以使用ibv_poll_cq()调用等待它完成操作。
send_wr.send_flags = IBV_SEND_SIGNALED;
send_wr.next = nullptr;
auto result = ibv_post_send(queue_pair_, &send_wr, &bad_wr);
free(send_sge);
return result == 0 ? true : false;
}
RDMA READ / RDMA WRITE#
类似地,您可以使用postSendRequest()发送RDMA WRITE或RDMA READ请求,但操作码不同:
- RDMA READ:
IBV_WR_RDMA_READ - RDMA WRITE:
IBV_WR_RDMA_WRITE有关SEND WR操作码详情,请参见[manual]。
对于RDMA READ/WRITE,您必须在ibv_send_wr中指定其他参数。例如,RDMA READ:
bool postRDMAReadRequest(const std::vector<struct ibv_mr*>& sge, struct ibv_mr* peer_memory_region) {
struct ibv_send_wr rdma_wr, ...;
rdma_wr.wr.rdma.remote_addr = peer_memory_region->addr;
rdma_wr.wr.rdma.rkey = peer_memory_region->rkey;
rdma.wr.opcode = IBV_WR_RDMA_READ;
// 其他部分相同
}
这个postRDMAReadRequest()函数从远程对等节点的peer_memory_region读取数据,并将其散布到sge中的ibv_mr中。
轮询完成
当设备完成操作时,它会将相应的工作完成(wc)条目创建到已连接的完成队列中(在创建队列对时指定完成队列。请参阅Section 4)。
基本上,我们可以使用轮询完成队列来检查工作是否完成。
轮询并不是唯一的工作完成检测方式。RDMA提供了一种通知机制,不过轮询通常更快(低延迟)进行检测,因为通知需要进行多次上下文切换、进程调度等操作。
更多详情可以参考7。本文将不涉及该内容,只讨论轮询的方式。
我们使用 ibv_poll_cq 来轮询完成队列。它是一种繁忙的轮询方式,会消耗一个CPU核,但具有较低的延迟。
bool pollCompletion(struct ibv_cq* cq) {
struct ibv_wc wc;
int result;
do {
// ibv_poll_cq 返回已完成的WC数量,
// 如果返回0,则表示没有接收到新的工作完成。
// 这里,第二个参数指定了轮询检查的WC数量,
// 但是如果给定的数量超过1,将会在使用g++8进行编译时触发堆栈溢出检测。
result = ibv_poll_cq(cq, 1, &wc);
} while (result == 0);
if (result > 0 && wc.status == ibv_wc_status::IBV_WC_SUCCESS) {
// 成功
return true;
}
// 你可以通过 wc.wr_id 来确定哪个WR失败了。
printf("工作完成状态为 %s 时轮询失败(工作请求ID:%llu)\n", ibv_wc_status_str(wc.status), wc.wr_id);
return false;
}
ibv_poll_cq 返回WC的数量。由于我们指定最多等待一个WC,所以结果只能是 0、1 或者负数(表示发生了错误)。
- RDMA Aware Programming User Manual ↩︎
- Infiniband Adapter Card Brochure ↩︎
- InfiniBand: An Introduction + Simple IB verbs program with RDMA Write ↩︎
- [Verbs Programming Tutorial](https://www.csm.ornl.gov/workshops/openshmem2013/documents/presentations_and_tutorials/Tutorials/Verbs programming tutorial-final.pdf) ↩︎
- QP State Machine ↩︎
- Building a block storage application on OFED - Challenges ↩︎
- ibv_req_notify_cq() ↩︎
- introduction-to-programming-infiniband
评论