Nvidia GPU Direct RDMA技术
1. 概述
GPUDirect RDMA是在Kepler类GPU和CUDA 5.0中引入的一项技术,它使用PCI Express的标准功能在GPU和第三方对等设备之间建立了直接数据交换路径。第三方设备的示例包括:网络接口,视频采集设备,存储适配器。GPUDirect RDMA适用于Tesla和Quadro GPU。
这种技术有一些限制,其中最重要的是两个设备必须共享相同的上游PCI Express root complex。
一些限制取决于所使用的平台,并且在当前/未来的产品中可能会取消。
必须对设备驱动程序进行一些简单的更改,以便与各种硬件设备启用此功能。本文介绍了该技术,并描述了在Linux上启用,到 NVIDIA GPU 的 GPUDirect RDMA 连接所需的步骤。
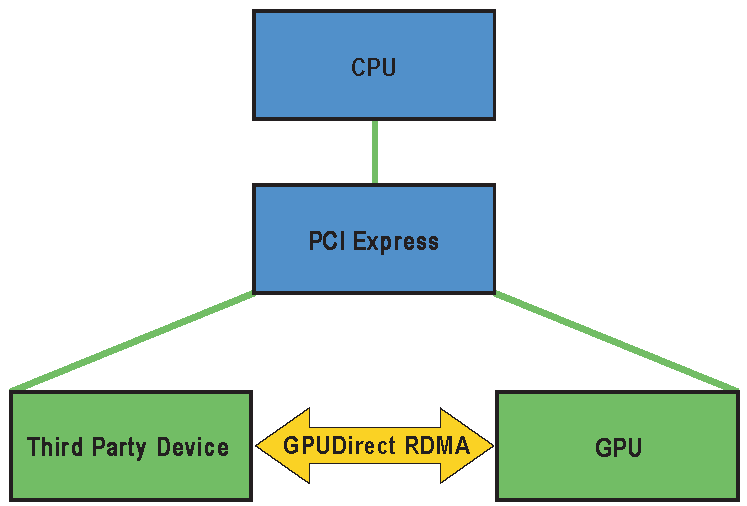
Linux设备驱动模型中的GPUDirect RDMA
1.1. GPUDirect RDMA的工作原理
在两个对等设备之间建立GPUDirect RDMA通信时,从PCI Express设备的角度来看,所有物理地址都是相同的。在此物理地址空间内,有称为PCI BAR的线性窗口(PCI设备可以要求操作系统/BIOS将物理地址空间的某个区域映射到它们。这些区域通常称为BAR(Base Address Registers))。每个设备最多有6个BAR寄存器,因此它可以拥有多达6个活动的32位BAR区域。64位BAR占用两个BAR寄存器。
PCI Express设备以与对系统内存发出的方式相同的方式向对等设备的BAR地址发出读写。
传统上,类似BAR窗口的资源通过使用CPU的MMU将其映射到用户或内核地址空间,作为内存映射I/O(MMIO,Memory-mapped I/O (MMIO) region)地址。然而,由于当前操作系统没有足够的机制来在驱动程序之间交换MMIO区域,NVIDIA内核驱动程序导出了执行必要的地址转换和映射的函数。
内存映射I/O(MMIO)区域是计算机体系结构中的一种机制,用于访问设备的I/O寄存器。在MMIO中,设备I/O寄存器被映射到计算机的内存地址空间中的特定区域。通过读取和写入这些内存地址,可以与设备进行通信和控制。
要将GPUDirect RDMA支持添加到设备驱动程序中,必须修改内核驱动程序中的一小段地址映射代码。此代码通常位于现有对get_user_pages()的调用附近。
与标准DMA传输相比,涉及GPUDirect RDMA的API和控制流非常相似。
有关更多硬件详细信息,请参阅支持的系统和PCI BAR大小。
1.2. 标准DMA传输
首先,我们概述了从用户空间发起的标准DMA传输。在此场景中,存在以下组件:
- 用户空间程序
- 用户空间通信库
- 用于进行DMA传输的设备的内核驱动程序
流程如下:
- 用户空间程序通过用户空间通信库请求传输。此操作接受数据的指针(虚拟地址)和大小(以字节为单位)。
- 通信库必须确保与虚拟地址和大小对应的内存区域已准备好进行传输。如果尚未准备好,则必须由内核驱动程序来处理(下一步)。
- 内核驱动程序从用户空间通信库接收虚拟地址和大小。然后,它请求内核将虚拟地址范围转换为物理页的列表,并确保它们准备好进行传输。我们将此操作称为“固定内存”。
- 内核驱动程序使用页列表来配置物理设备的DMA引擎。
- 通信库启动传输。
- 传输完成后,通信库最终应清理用于固定内存的任何资源。我们将此操作称为“解除固定内存”。
1.3. GPUDirect RDMA传输
支持GPUDirect RDMA传输的通信需要引入上述序列的若干变化。
根据[UVA CUDA内存管理基础](#UVA CUDA内存管理基础)的描述,使用CUDA库的程序的地址空间在GPU和CPU虚拟地址之间进行了划分,通信库必须为它们实现两条单独的路径。
首先,引入了两个新组件:
- 用户空间CUDA库: 用户空间的CUDA库提供了一个函数,使通信库可以区分CPU和GPU地址。此外,对于GPU地址,它返回了额外的元数据,用于唯一标识由该地址表示的GPU内存。有关详细信息,请参见用户空间API。
- NVIDIA内核驱动程序: CPU地址和GPU地址之间的差异在于内存的固定和解除固定的方式。对于CPU内存,这是由内置的Linux内核函数(
get_user_pages()和put_page())处理的。然而,在GPU内存的情况下,固定和解除固定必须由NVIDIA内核驱动程序提供的函数处理。有关详细信息,请参见固定GPU内存和解除固定GPU内存。
一些硬件注意事项在支持的系统和[PCI BAR大小](#PCI BAR大小)中有详细解释。
2. 设计注意事项
在设计使用GPUDirect RDMA的系统时,有一些考虑因素需要考虑。
2.1. 延迟取消固定优化
将GPU设备内存固定在BAR中是一项昂贵的操作,需要花费数毫秒的时间。因此,应该设计应用程序以尽量减少这种开销。
使用GPUDirect RDMA的最直接实现方式是在每次传输之前固定内存,并在传输完成后立即取消固定。然而,这通常表现较差,因为固定和取消固定内存是昂贵的操作。然而,执行RDMA传输所需的其他步骤可以在不进入内核的情况下快速完成(DMA列表可以使用MMIO寄存器/命令列表进行缓存和重播)。
因此,延迟取消固定内存是实现高性能RDMA的关键。这意味着即使传输完成后仍将内存固定住。这利用了同一内存区域很可能会用于将来的DMA传输,从而节省了固定/取消固定操作的开销。
延迟取消固定的示例实现可以保持一组固定的内存区域,并且只有在区域的总大小达到某个阈值时或者由于BAR空间耗尽而无法固定新区域时(参见PCI BAR大小)才取消固定其中一部分(例如,取消最近未使用的部分)。
2.2. 注册缓存
通信中间件通常使用一种称为注册缓存或固定缓存的优化方式来最小化固定开销。通常,它已经存在于主机内存中,实现了延迟取消固定、LRU反注册等功能。对于网络中间件,这些缓存通常在用户空间中实现,因为它们与能够进行用户模式消息注入的硬件组合使用。CUDA UVA内存地址布局通过考虑一些设计注意事项使GPU内存固定与这些缓存一起工作。在CUDA环境中,这一点更加重要,因为可以固定的内存量可能比主机内存受到更大限制。
由于GPU BAR空间通常使用64KB页进行映射,因此保持一个以64KB边界为基础的区域缓存更具资源效率。而且,由于两个位于同一64KB边界内的内存区域将分配并返回相同的BAR映射,所以更加高效。
注册缓存通常依赖于能够拦截发生在用户应用程序中的解除分配事件,以便可以取消固定内存并释放重要的硬件资源,例如网络卡上的资源。要为GPU内存实现类似的机制,实现有两个选项:
- 仪器化所有CUDA分配和解除分配API。
- 使用标签检查函数来跟踪解除分配和重分配。请参见基于缓冲区ID标签检查的注册缓存。
有一个示例应用程序7_CUDALibraries/cuHook展示了如何在运行时拦截对CUDA API的调用,可以用来检测GPU内存的分配和解除分配。
虽然拦截CUDA API超出了本文档的范围,但从CUDA 6.0开始提供了执行标签检查的方法。它涉及使用cuPointerGetAttribute()(如果需要更多属性,可使用cuPointerGetAttributes())中的CU_POINTER_ATTRIBUTE_BUFFER_ID属性来检测内存缓冲区的解除分配或重分配。如果发生重分配,API将返回不同的ID值;如果缓冲区地址不再有效,则返回错误。有关API用法,请参见用户空间API。
注意: 使用标签检查在每个内存缓冲区使用中引入了一个额外的CUDA API调用,因此当附加延迟不是问题时,这种方法最为合适。
2.3. 取消固定回调函数
当第三方设备驱动使用nvidia_p2p_get_pages()固定GPU页面时,它还必须提供一个回调函数,NVIDIA驱动程序将调用该函数,如果需要撤销对映射的访问权限。此回调函数是同步发生的,给第三方驱动程序提供了清理和删除与所讨论的页面相关的任何引用(即等待尚未完成的DMA)的机会。使用者回调函数可能会阻塞几毫秒,尽管建议回调尽快完成。在回调中等待GPU执行任何操作可能会导致死锁,因此必须注意避免。
回调必须调用nvidia_p2p_free_page_table()(而不是nvidia_p2p_put_pages())以释放page_table指向的内存。只有在从回调函数返回后,NVIDIA驱动程序才会取消映射的内存区域。
请注意,回调将在以下两种情况下被调用:
- 如果用户空间程序在第三方内核驱动程序有机会使用
nvidia_p2p_put_pages()解除固定内存之前显式释放相应的GPU内存,例如cuMemFree,cuCtxDestroy等。 - 由于进程早期退出的结果。
在后一种情况下,第三方内核驱动程序的文件描述符关闭和NVIDIA内核驱动程序的文件描述符关闭之间可能存在拆卸顺序问题。如果首先关闭NVIDIA内核驱动程序的文件描述符,将调用nvidia_p2p_put_pages()回调。
正确的软件设计非常重要,因为NVIDIA内核驱动程序会在调用回调之前使用锁来保护自身免受可重入性问题的影响。第三方内核驱动程序几乎肯定会采取类似的措施,因此如果不仔细考虑,可能会出现死锁或活锁的情况。
2.4. 支持的系统
尽管GPUDirect RDMA在第三方设备和NVIDIA GPU之间正常工作的理论要求只是它们共享相同的根复杂性,但存在错误(主要是芯片组中的错误),导致在某些设置中性能不佳或根本无法工作。
我们可以区分三种情况,取决于GPU和第三方设备之间路径上的内容:
- 只有PCIe交换机
- 单个CPU/IOH
- CPU/IOH <-> QPI/HT <-> CPU/IOH
第一种情况,即只有PCIe交换机在路径上,是最理想的,可以获得最佳性能。
第二种情况,即涉及到单个CPU/IOH,可以工作,但性能较差(特别是在某些处理器架构上,对等读取带宽严重受限)。
最后一种情况,即路径经过QPI/HT链路,可能极其受性能限制,甚至无法可靠工作。
提示: 可以使用lspci命令检查PCI拓扑结构:
$ lspci -t
平台支持
对于IBM POWER8平台,不支持GPUDirect RDMA和P2P,但也没有显式禁用。在运行时可能无法正常工作。
GPUDirect RDMA从CUDA 10.1开始支持Jetson AGX Xavier平台,并且从CUDA 11.2开始支持基于Linux的Drive AGX Xavier平台。有关详细信息,请参阅移植到Tegra部分。在ARM64上,所需的对等功能取决于特定平台的硬件和软件。因此,虽然非Jetson和非Drive平台上并没有显式禁用GPUDirect RDMA,但不能保证它将完全正常工作。
IOMMU
GPUDirect RDMA目前依赖于不同PCI设备的物理地址视角上的所有物理地址相同。这使其与执行除1:1之外任何形式的翻译的IOMMU不兼容,因此必须禁用或配置为透明传输以使GPUDirect RDMA正常工作。
2.5. PCI BAR大小
PCI设备可以要求操作系统/BIOS将物理地址空间的某个区域映射到它们。这些区域通常称为BAR(Base Address Registers)。NVIDIA GPU目前公开多个BAR,并且其中某些BAR可以支持任意设备内存,从而使GPUDirect RDMA成为可能。每个GPU可用于GPUDirect RDMA的最大BAR大小因GPU而异。例如,目前Kepler类GPU上可用的最小BAR大小为256MB。其中32MB目前保留用于内部使用。这些大小可能会有所变化。
在某些Tesla级GPU上启用了大BAR功能,例如将BAR1大小设置为16GB或更大。大BAR可能会对BIOS造成问题,特别是在旧的主板上,与对32位操作系统的兼容性支持有关。在这些主板上,引导过程可能会在早期的POST阶段停止,或者GPU可能被错误配置,因此无法使用。如果出现这种情况,可能需要启用一些特殊的BIOS功能来处理大BAR问题。
2.6. 令牌的使用
从CUDA 6.0开始,令牌应弃用,尽管仍然支持。
如用户空间API和内核API中所示,将内存固定和取消固定的一种方法需要除了GPU虚拟地址之外的两个令牌。
这些令牌,p2pToken和vaSpaceToken,用于唯一标识一个GPU VA空间。仅凭进程标识符无法标识一个GPU VA空间。
这些令牌在单个CUDA上下文中是一致的(即,同一个CUDA上下文中通过cudaMalloc()获得的所有内存将具有相同的p2pToken和vaSpaceToken)。但是,给定的GPU虚拟地址在其整个生命周期中不一定要映射到相同的上下文/GPU。作为一个具体的例子:
cudaSetDevice(0)
ptr0 = cudaMalloc();
cuPointerGetAttribute(&return_data, CU_POINTER_ATTRIBUTE_P2P_TOKENS, ptr0);
// 返回 [p2pToken = 0xabcd, vaSpaceToken = 0x1]
cudaFree(ptr0);
cudaSetDevice(1);
ptr1 = cudaMalloc();
assert(ptr0 == ptr1);
// 尽管没有保证,但CUDA驱动程序可以自由重用VA,即使在不同的GPU上
cuPointerGetAttribute(&return_data, CU_POINTER_ATTRIBUTE_P2P_TOKENS, ptr0);
// 返回 [p2pToken = 0x0123, vaSpaceToken = 0x2]
也就是说,在程序执行过程中,同一个地址在传递给 cuPointerGetAttribute 时可能会返回不同的令牌。因此,第三方通信库必须对其操作的每个指针调用 cuPointerGetAttribute()。
安全性影响
这两个令牌作为NVIDIA内核驱动程序的身份验证机制。如果你知道这些令牌,你可以映射与它们对应的地址空间,并且NVIDIA内核驱动程序不会执行任何额外的检查。64位的 p2pToken 是随机化的,以防止对手猜测。
当没有使用令牌时,NVIDIA驱动程序将内核API限制为拥有内存分配的进程。
2.7. 同步与内存顺序
GPUDirect RDMA引入了一个针对第三方设备的新的独立GPU数据流路径,重要的是要了解这些设备如何与GPU的宽松内存模型交互。
- 正确注册CUDA内存的BAR映射是必需的,以确保该映射与CUDA API对该内存的操作保持一致。
- 只有CUDA同步和工作提交API提供GPUDirect RDMA操作的内存排序。
为了保证CUDA API的一致性注册
注册是必要的,以确保CUDA API内存操作对于BAR映射可见发生在API调用将控制返回给调用的CPU线程之前。这为使用GPUDirect RDMA映射的设备提供了一个内存的一致视图,当在线程中调用CUDA API之后被调用。这是CUDA API的一个更加保守的工作模式,并禁用了优化,因此可能会对性能产生负面影响。
可以通过使用具有CU_POINTER_ATTRIBUTE_SYNC_MEMOPS属性的cuPointerSetAttribute()调用或在使用传统路径时检索缓冲区的p2p令牌来为每个分配粒度启用此行为。更多细节请参阅用户空间API。
一个例子是cuMemcpyDtoD()和随后的GPUDirect RDMA读取操作之间的读-写依赖关系。作为优化,设备之间的内存复制通常会在将复制排队到GPU调度程序后异步返回给调用线程。然而,在这种情况下,这会导致通过BAR映射读取到不一致的数据,因此这个优化被禁用,复制在CUDA API返回之前完成。
用于内存顺序的CUDA API
只有由CPU发起的CUDA API提供了GPU观察到的GPUDirect内存操作的顺序。也就是说,尽管三方设备已经发出了所有的PCIE事务,正在运行的GPU内核或复制操作可能观察到陈旧的数据或乱序到达的数据,直到后续CPU发起的CUDA工作提交或同步API。为了确保内存更新对CUDA内核或复制可见,实现应确保在将控制返回给将调用依赖CUDA API的CPU线程之前所有写入GPU BAR。
一个网络通信场景的示例是在第三方网络设备完成网络RDMA写操作,并将数据写入GPU BAR映射。尽管通过GPU BAR或CUDA内存复制操作读取已写入的数据将返回新写入的数据,但同时运行的GPU内核可能会观察到过时的数据、部分写入的数据或乱序写入的数据。
简而言之,GPU内核与并发RDMA GPUDirect操作完全不一致,在这种情况下访问第三方设备覆盖的内存将被视为数据竞争。为了解决这种不一致性并消除数据竞争,DMA写操作必须相对于启动依赖的GPU内核的CPU线程完成。
3. 如何执行特定任务
3.1. 显示GPU BAR空间
从CUDA 6.0开始,NVIDIA SMI实用程序提供了转储BAR1内存使用情况的功能。它可以用于了解GPUDirect RDMA映射所消耗的主要资源BAR空间的应用程序使用情况。
$ nvidia-smi -q
...
BAR1 Memory Usage
Total : 256 MiB
Used : 2 MiB
Free : 254 MiB
...
GPU内存被固定大小的块固定,所以这里反映的空间量可能会出乎意料。此外,驱动程序保留了一定数量的BAR空间供内部使用,因此并非所有可用的内存都可以通过GPUDirect RDMA使用。请注意,通过nvmlDeviceGetBAR1MemoryInfo() NVML API也可以以编程方式提供相同的功能。
3.2. 固定GPU内存
-
正确的行为需要在内存地址上使用
cuPointerSetAttribute()以启用CUDA驱动程序中的适当同步行为。参见 同步和内存排序 章节。void pin_buffer(void *address, size_t size) { unsigned int flag = 1; CUresult status = cuPointerSetAttribute(&flag, CU_POINTER_ATTRIBUTE_SYNC_MEMOPS, address); if (CUDA_SUCCESS == status) { // GPU路径 pass_to_kernel_driver(address, size); } else { // CPU路径 // ... } }这是为了使CUDA驱动程序以特殊方式处理GPU内存缓冲区,以便CUDA内存传输始终与主机同步。有关
cuPointerSetAttribute()的详细信息,请参阅用户空间API。 -
在内核驱动程序中,调用
nvidia_p2p_get_pages()。// 用于边界对齐要求 #define GPU_BOUND_SHIFT 16 #define GPU_BOUND_SIZE ((u64)1 << GPU_BOUND_SHIFT) #define GPU_BOUND_OFFSET (GPU_BOUND_SIZE-1) #define GPU_BOUND_MASK (~GPU_BOUND_OFFSET) struct kmd_state { nvidia_p2p_page_table_t *page_table; // ... }; void kmd_pin_memory(struct kmd_state *my_state, void *address, size_t size) { // 按照NVIDIA内核驱动程序的要求进行适当对齐 u64 virt_start = address & GPU_BOUND_MASK; size_t pin_size = address + size - virt_start; if (!size) return -EINVAL; int ret = nvidia_p2p_get_pages(0, 0, virt_start, pin_size, &my_state->page_table, free_callback, &my_state); if (ret == 0) { // 成功固定,page_table可被访问 } else { // 固定失败 } }注意在调用固定函数之前将起始地址对齐到64KB边界。
如果函数执行成功,内存已经被固定,并且可以使用page_table条目来对设备的DMA引擎进行编程。有关nvidia_p2p_get_pages()的详细信息,请参见Kernel API。
3.3. 解除固定GPU内存
在内核驱动程序中,调用nvidia_p2p_put_pages()。
void unpin_memory(void *address, size_t size, nvidia_p2p_page_table_t *page_table)
{
nvidia_p2p_put_pages(0, 0, address, size, page_table);
}
有关nvidia_p2p_put_pages()的详细信息,请参见Kernel API。
从CUDA 6.0开始,应使用零作为令牌参数。请注意,必须在与发出相应的nvidia_p2p_get_pages()的进程上下文中调用nvidia_p2p_put_pages()。
3.4. 处理释放回调
-
如果需要撤销映射,NVIDIA内核驱动程序将根据
nvidia_p2p_get_pages()调用中指定的free_callback(data)来调用自由回调函数。有关详细信息,请参见Kernel API和Unpin Callback。 -
回调函数会等待挂起的传输,然后清理页表分配。
void free_callback(void *data) { my_state *state = data; wait_for_pending_transfers(state); nvidia_p2p_free_pages(state->page_table); } -
NVIDIA内核驱动程序处理取消映射,因此不应调用
nvidia_p2p_put_pages()。
3.5. A Registration Cache的缓冲区ID标签检查
请记住,不建议针对延迟敏感的实现构建基于缓冲区ID标签检查的解决方案。
相反,建议对CUDA分配和释放API进行仪器化,以提供回调函数给注册缓存,从而可以将标签检查开销从关键路径中删除。
-
第一次遇到并确定尚未固定的设备内存缓冲区时,将创建固定的映射,并检索并在缓存条目中存储相关的缓冲区ID。
cuMemGetAddressRange()函数可用于获取整个分配的大小和起始地址,然后可以使用它来固定。由于nvidia_p2p_get_pages()需要一个64K对齐的指针,因此直接对齐缓存地址很有用。此外,由于BAR空间目前以64KB的块映射,将整个固定舍入到64KB更节省资源。// struct buf表示注册缓存的条目 struct buf { CUdeviceptr pointer; size_t size; CUdeviceptr aligned_pointer; size_t aligned_size; int is_pinned; uint64_t id; // 在固定后获取的缓冲区ID }; -
一旦创建,每次使用注册缓存条目之前,必须先检查其有效性。一种方法是使用CUDA提供的缓冲区ID作为标签来检查释放或重新分配。
int buf_is_gpu_pinning_valid(struct buf* buf) {
uint64_t buffer_id;
int retcode;
assert(buf->is_pinned);
// 获取当前缓冲区的缓冲区id
retcode = cuPointerGetAttribute(&buffer_id, CU_POINTER_ATTRIBUTE_BUFFER_ID, buf->pointer);
// 如果返回值为CUDA_ERROR_INVALID_VALUE,则表示设备指针不再有效,可能已经被释放
if (CUDA_ERROR_INVALID_VALUE == retcode) {
return ERROR_INVALIDATED;
} else if (CUDA_SUCCESS != retcode) {
// 处理更严重的错误
return ERROR_SERIOUS;
}
// 如果缓冲区id与原始的缓冲区id不相等,则表示原始缓冲区已被释放,需要使映射失效并重新固定缓冲区
if (buf->id != buffer_id)
return ERROR_INVALIDATED;
return 0;
}
当缓冲区标识符改变时,相应的内存缓冲区已被重新分配,因此相应的内核空间页表将不再有效。在这种情况下,内核空间的nvidia_p2p_get_pages()回调将会被调用。因此,缓冲区ID提供了一个标签,以保持固定缓存与内核空间页表的一致性,而不需要内核驱动程序向用户空间上调。
如果从cuPointerGetAttribute()返回CUDA_ERROR_INVALID_VALUE,则程序应假设内存缓冲区已被释放,或者以其他方式不是有效的GPU内存缓冲区。
在这两种情况下,必须使相应的缓存条目无效。
// 在注册缓存代码中
if (buf->is_pinned && !buf_is_gpu_pinning_valid(buf)) {
regcache_invalidate_entry(buf);
pin_buffer(buf);
}
3.6. 将内核模块链接到nvidia.ko
- 运行提取脚本:
./NVIDIA-Linux-x86_64-<version>.run -x
这将提取NVIDIA驱动程序和内核包装程序。
- 切换到输出目录:
cd <output directory>/kernel/
- 在此目录中,为您的内核构建NVIDIA模块:
make module
完成后,您的内核构建目录下的Module.symvers文件将包含nvidia.ko的符号信息。
- 使用以下行修改您的内核模块构建过程:
KBUILD_EXTRA_SYMBOLS := <path to kernel build directory>/Module.symvers
3.7. 使用nvidia-peermem
NVIDIA GPU驱动程序包提供了一个内核模块nvidia-peermem,它为基于NVIDIA InfiniBand的HCAs(Host Channel Adapters)提供了对NVIDIA GPU内存的直接点对点读写访问。它允许GPUDirect RDMA应用在不需要将数据复制到主机内存的情况下使用GPU计算能力。
此功能支持使用NVIDIA ConnectX®-3 VPI或更新的适配器。它适用于InfiniBand和RoCE(以太网上RDMA)技术。
NVIDIA OFED(Open Fabrics Enterprise Distribution)或MLNX_OFED在InfiniBand Core和对等内存客户端(如NVIDIA GPU)之间引入了一个API。nvidia-peermem模块通过使用NVIDIA GPU驱动程序提供的点对点API将NVIDIA GPU注册到InfiniBand子系统。
要加载和使用nvidia-peermem,内核必须具有对RDMA对等内存的必需支持,可以通过向内核添加额外补丁或通过MLNX_OFED来满足前提条件。
可能已在系统上安装并加载了GitHub项目中的nv_peer_mem模块。安装nvidia-peermem不会影响现有的nv_peer_mem模块的功能。但是,要加载和使用nvidia-peermem,用户必须禁用nv_peer_mem服务。此外,建议卸载nv_peer_mem软件包,以避免与nvidia-peermem的冲突,因为一次只能加载一个模块。
停止nv_peer_mem服务:
# service nv_peer_mem stop
停止服务后检查是否仍加载了nv_peer_mem.ko:
# lsmod | grep nv_peer_mem
如果仍加载nv_peer_mem.ko,使用以下命令卸载:
# rmmod nv_peer_mem
卸载nv_peer_mem软件包:
适用于基于DEB的操作系统:
# dpkg -P nvidia-peer-memory
# dpkg -P nvidia-peer-memory-dkms
适用于基于RPM的操作系统:
# rpm -e nvidia_peer_memory
在确保有内核支持并安装了GPU驱动程序之后,可以使用以下命令以root权限在终端窗口中加载nvidia-peermem:
# modprobe nvidia-peermem
注意:如果在安装MLNX_OFED之前已安装了NVIDIA GPU驱动程序,则必须卸载并重新安装GPU驱动程序,以确保nvidia-peermem使用由MLNX_OFED提供的RDMA API编译。
4. 参考资料
4.1. UVA CUDA内存管理基础
64位进程上运行的Fermi和Kepler GPU上,CUDA 4.0及更高版本默认启用统一虚拟寻址(UVA,Uniform Virtual Addressing)内存地址管理系统。UVA内存管理的设计为GPUDirect RDMA的操作提供了基础。在支持UVA的配置中,当CUDA运行时初始化时,应用的虚拟地址(VA)范围被分成两个区域:CUDA管理的VA范围和操作系统管理的VA范围。所有CUDA管理的指针都在此VA范围内,并且范围始终位于进程的VA空间的前40位内。
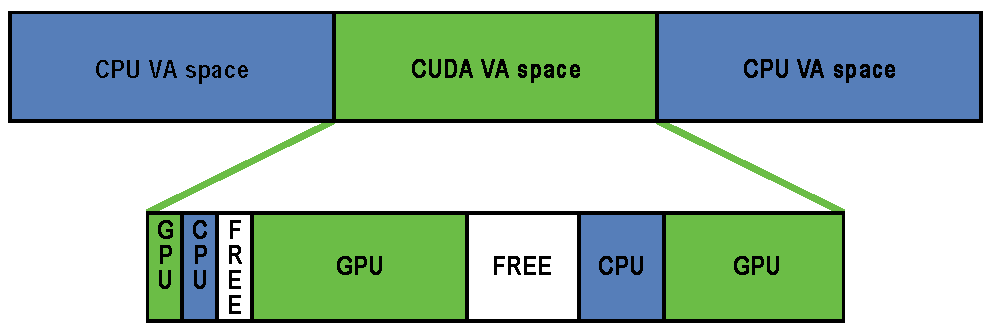
在CUDA VA空间中,地址可以细分为三种类型:
-
GPU
由GPU内存支持的页面。主机将无法访问该页面,而且该地址在主机上永远不会有物理备份。从CPU引用指向GPU VA的指针将触发段错误。
-
CPU
由CPU内存支持的页面。主机和GPU都可以同时使用相同的VA访问该页面。
-
FREE
这些VA由CUDA保留供将来分配使用。
这种划分允许CUDA运行时通过指针在保留的CUDA VA空间内确定内存对象的物理位置。
地址以页面粒度进行划分成这些类别;页面内的所有内存都属于同一类型。请注意,GPU页面的大小可能与CPU页面的大小不同。CPU页面通常为4KB,而Kepler系列GPU的GPU页面为64KB。GPUDirect RDMA仅在位于这个CUDA VA空间内的GPU页面上操作(由cudaMalloc()创建)。
4.2. 用户空间 API
数据结构
typedef struct CUDA_POINTER_ATTRIBUTE_P2P_TOKENS_st {
unsigned long long p2pToken;
unsigned int vaSpaceToken;
} CUDA_POINTER_ATTRIBUTE_P2P_TOKENS;
函数cuPointerSetAttribute()
CUresult cuPointerSetAttribute(void *data, CUpointer_attribute attribute, CUdeviceptr pointer);
在GPUDirect RDMA范围内,当attribute参数传递CU_POINTER_ATTRIBUTE_SYNC_MEMOPS时,此函数非常有用。
unsigned int flag = 1;
cuPointerSetAttribute(&flag, CU_POINTER_ATTRIBUTE_SYNC_MEMOPS, pointer);
参数
-
data [in]
一个指向
unsigned int类型变量的指针,包含一个布尔值。 -
attribute [in]
在GPUDirect RDMA范围内应该始终为
CU_POINTER_ATTRIBUTE_SYNC_MEMOPS。 -
pointer [in]
一个指针。
返回值
-
CUDA_SUCCESS如果指针指向GPU内存,并且CUDA驱动程序能够为整个设备内存分配设置新的行为。
-
其他任何返回值
如果指针指向CPU内存。
该函数用于显式地在由pointer指示的整个内存分配上启用严格的同步行为,从而禁用可能与并发RDMA和CUDA内存复制操作冲突的所有数据传输优化。该API具有CUDA同步行为,因此它应该被视为昂贵的,并且可能只在每个缓冲区上调用一次。
函数cuPointerGetAttribute()
CUresult cuPointerGetAttribute(const void *data, CUpointer_attribute attribute, CUdeviceptr pointer);
该函数与GPUDirect RDMA相关的两个不同属性:CU_POINTER_ATTRIBUTE_P2P_TOKENS和CU_POINTER_ATTRIBUTE_BUFFER_ID。
警告
CU_POINTER_ATTRIBUTE_P2P_TOKENS已在CUDA 6.0中被弃用
当将CU_POINTER_ATTRIBUTE_P2P_TOKENS作为attribute传递时,data是指向CUDA_POINTER_ATTRIBUTE_P2P_TOKENS的指针:
CUDA_POINTER_ATTRIBUTE_P2P_TOKENS tokens;
cuPointerGetAttribute(&tokens, CU_POINTER_ATTRIBUTE_P2P_TOKENS, pointer);
在这种情况下,函数将返回两个用于Kernel API的令牌。
参数
-
data [out]
结构体
CUDA_POINTER_ATTRIBUTE_P2P_TOKENS,包含两个令牌。 -
attribute [in]
在GPUDirect RDMA范围内应始终为
CU_POINTER_ATTRIBUTE_P2P_TOKENS。 -
pointer [in]
一个指针。
返回值
-
CUDA_SUCCESS如果指针指向GPU内存。
-
其他任何返回值
如果指针指向CPU内存。
该函数可以在任何时候调用,包括CUDA初始化之前,它具有与CU_POINTER_ATTRIBUTE_SYNC_MEMOPS相同的CUDA同步行为,因此应该被视为昂贵的,并且每个缓冲区只调用一次。
注意,tokens中设置的值在用户程序的生命周期中对于相同的pointer值可能会有所不同。有关具体示例,请参见Tokens Usage。
请注意,出于安全原因,p2pToken中设置的值将被随机化,以防止敌方猜测。
在CUDA 6.0中,引入了一个新的属性,用于检测内存重新分配。
当将CU_POINTER_ATTRIBUTE_BUFFER_ID作为attribute传递时,data应指向一个64位无符号整数变量,如uint64_t。
uint64_t buf_id;
cuPointerGetAttribute(&buf_id, CU_POINTER_ATTRIBUTE_BUFFER_ID, pointer);
参数
-
data [out]
一个指向64位变量的指针,用于存储缓冲区ID。
-
attribute [in]
CU_POINTER_ATTRIBUTE_BUFFER_ID的枚举。 -
pointer [in]
一个指向GPU内存的指针。
返回值
-
CUDA_SUCCESS如果指针指向GPU内存。
-
其他任何返回值
如果指针指向CPU内存。
以下是一些一般性的备注:
cuPointerGetAttribute()和cuPointerSetAttribute()是仅限CUDA驱动程序API的函数。- 特别地,
cuPointerGetAttribute()不等同于cudaPointerGetAttributes(),因为所需的功能仅在前者函数中存在。这并不限制GPUDirect RDMA可以使用的范围,因为cuPointerGetAttribute()与CUDA Runtime API兼容。 - 没有运行时API等效于
cuPointerGetAttribute()。这是因为CUDA运行时API到驱动API调用序列的额外开销会引入不必要的开销,并且cuPointerGetAttribute()可能位于关键路径上,例如通信库的关键路径。 - 如果可能的话,建议通过使用
cuPointerGetAttributes组合多个调用来减少调用次数。
函数cuPointerGetAttributes()
CUresult cuPointerGetAttributes(unsigned int numAttributes, CUpointer_attribute *attributes, void **data, CUdeviceptr ptr);
此函数可用于一次检查多个属性。与GPUDirect RDMA最相关的可能是CU_POINTER_ATTRIBUTE_BUFFER_ID,CU_POINTER_ATTRIBUTE_MEMORY_TYPE和CU_POINTER_ATTRIBUTE_IS_MANAGED。
4.3. Kernel API
以下声明可以在分发的NVIDIA Driver软件包中找到的nv-p2p.h头文件中找到。有关以下功能的参数和返回值的详细描述,请参阅该头文件中的内联文档。
预处理宏
NVIDIA_P2P_PAGE_TABLE_VERSION_COMPATIBLE()和NVIDIA_P2P_DMA_MAPPING_VERSION_COMPATIBLE()预处理宏旨在由第三方设备驱动程序调用以检查运行时二进制兼容性。
结构nvidia_p2p_page
typedef
struct nvidia_p2p_page {
uint64_t physical_address;
union nvidia_p2p_request_registers {
struct {
uint32_t wreqmb_h;
uint32_t rreqmb_h;
uint32_t rreqmb_0;
uint32_t reserved[3];
} fermi;
} registers;
} nvidia_p2p_page_t;
在nvidia_p2p_page结构中,只有physical_address字段与GPUDirect RDMA相关。
结构nvidia_p2p_page_table
typedef
struct nvidia_p2p_page_table {
uint32_t version;
uint32_t page_size;
struct nvidia_p2p_page **pages;
uint32_t entries;
uint8_t *gpu_uuid;
} nvidia_p2p_page_table_t;
在访问其他字段之前,应使用NVIDIA_P2P_PAGE_TABLE_VERSION_COMPATIBLE()检查页面表的version字段。
page_size字段根据nvidia_p2p_page_size_type枚举进行编码。
结构nvidia_p2p_dma_mapping
typedef
struct nvidia_p2p_dma_mapping {
uint32_t version;
enum nvidia_p2p_page_size_type page_size_type;
uint32_t entries;C
uint64_t *dma_addresses;
} nvidia_p2p_dma_mapping_t;
在访问其他字段之前,应将dma映射的version字段传递给NVIDIA_P2P_DMA_MAPPING_VERSION_COMPATIBLE()。
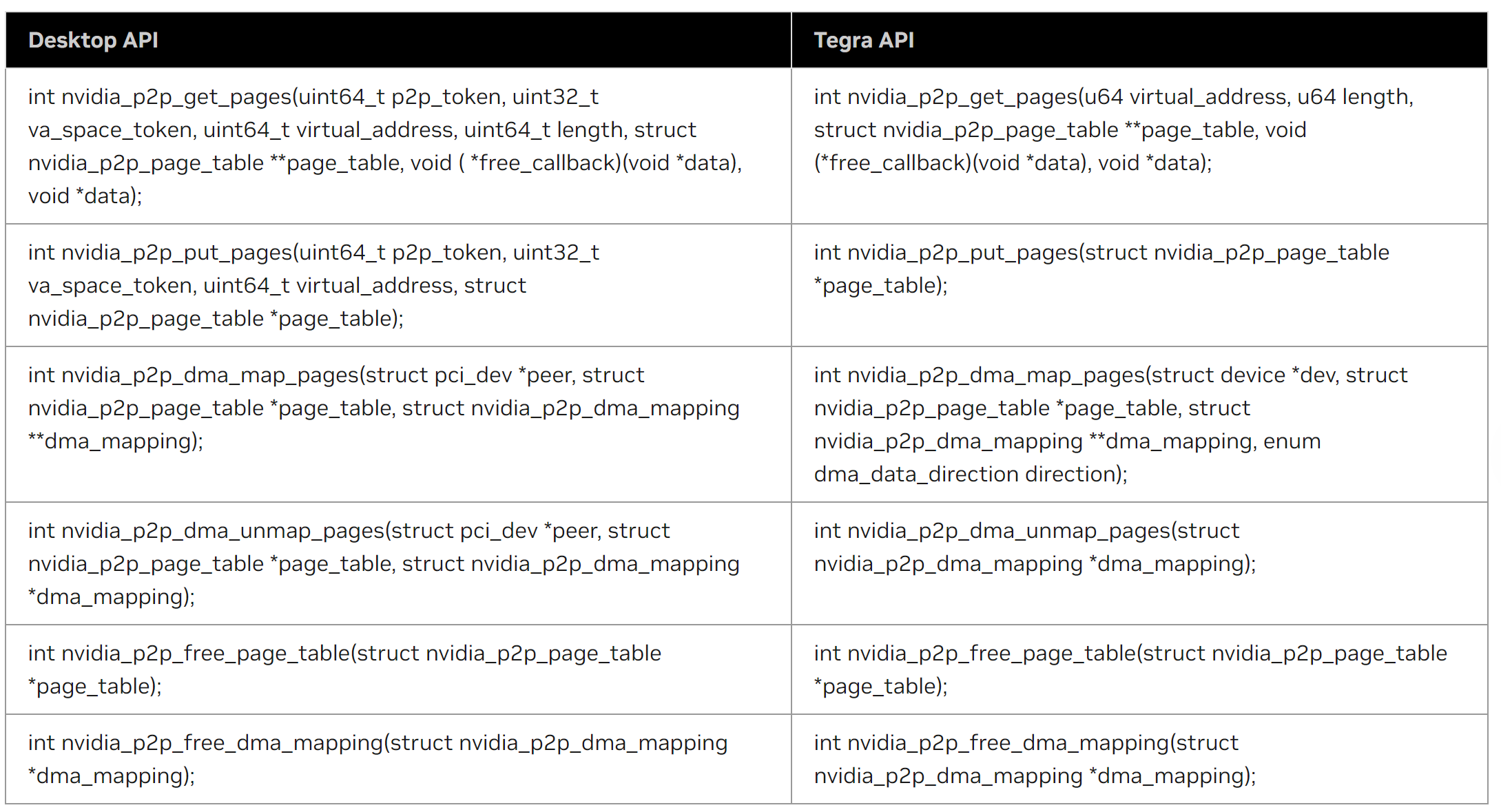
函数nvidia_p2p_get_pages()
int nvidia_p2p_get_pages(uint64_t p2p_token, uint32_t va_space_token,
uint64_t virtual_address,
uint64_t length,
struct nvidia_p2p_page_table **page_table,
void (*free_callback)(void *data),
void *data);
此函数使位于GPU虚拟内存范围下的页面对第三方设备可访问。
警告:这是一个昂贵的操作,应尽可能少进行执行-参见惰性取消固定优化。
函数nvidia_p2p_put_pages()
int nvidia_p2p_put_pages(uint64_t p2p_token, uint32_t va_space_token,
uint64_t virtual_address,
struct nvidia_p2p_page_table *page_table);
这个函数释放之前给第三方设备访问的一组页面。警告:不应该在“nvidia_p2p_get_pages()”回调中调用这个函数。
函数nvidia_p2p_free_page_table()
int nvidia_p2p_free_page_table(struct nvidia_p2p_page_table *page_table);
这个函数释放一个第三方的P2P页面表,应该在执行“nvidia_p2p_get_pages()”回调期间调用。
函数nvidia_p2p_dma_map_pages()
int nvidia_p2p_dma_map_pages(struct pci_dev *peer,
struct nvidia_p2p_page_table *page_table,
struct nvidia_p2p_dma_mapping **dma_mapping);
这个函数使使用nvidia_p2p_get_pages()获取的物理页面对第三方设备访问。
在那些PCIe资源的I/O地址与CPU用来访问这些资源的物理地址不同的平台上,这是必需的。
在一些平台上,这个函数依赖于正确实现的dma_map_resource() Linux内核函数。
函数nvidia_p2p_dma_unmap_pages()
int nvidia_p2p_dma_unmap_pages(struct pci_dev *peer,
struct nvidia_p2p_page_table *page_table,
struct nvidia_p2p_dma_mapping *dma_mapping);
这个函数取消映射之前通过nvidia_p2p_dma_map_pages()映射到第三方设备的物理页面。
不应该在nvidia_p2p_get_pages()的失效回调中调用它。
函数nvidia_p2p_free_dma_mapping()
int nvidia_p2p_free_dma_mapping(struct nvidia_p2p_dma_mapping *dma_mapping);
这个函数应该在nvidia_p2p_get_pages()的失效回调中调用。
请注意,I/O映射的释放可能会被延迟,例如在从失效回调返回后。
4.4. 移植到Tegra
从CUDA 10.1开始,Jetson AGX Xavier平台支持GPUDirect RDMA,从CUDA 11.2开始,DRIVE AGX Xavier基于Linux的平台和Jetson Orin平台也支持GPUDirect RDMA。从这一点开始,本文档将统称Jetson和Drive为Tegra。由于Tegra和Linux-Desktop之间的硬件和软件特定差异,已经开发的应用程序需要进行一些修改才能移植到Tegra。下面的子章节(4.4.1-4.4.3)简要介绍了必要的修改。
4.4.1. 更改内存分配器
在桌面上,GPUDirect RDMA允许应用程序仅使用cudaMalloc()分配的GPU页面进行操作。在Tegra上,应用程序需要将内存分配器从cudaMalloc()更改为cudaHostAlloc()。应用程序可以选择以下方法之一:
- 将返回的指针视为设备指针,前提是iGPU支持UVA或使用
cudaDeviceGetAttribute()查询时,cudaDevAttrCanUseHostPointerForRegisteredMem设备属性的值为非零值。 - 使用
cudaHostGetDevicePointer()获取与分配的主机内存对应的设备指针。一旦应用程序获得了设备指针,所有适用于标准GPUDirect解决方案的规则也适用于Tegra。
4.4.2. 修改内核API
下表中Tegra API列下的声明可以在NVIDIA驱动程序软件包中分发的nv-p2p.h头文件中找到。有关参数和返回值的详细说明,请参考该头文件中包含的内联文档。下表描述了Tegra相对于桌面的内核API变化。
4.4.3.其他亮点
-
请求的映射长度和基地址必须是4KB的倍数,否则会出错。
-
与桌面版本不同,当调用
nvidia_p2p_put_pages()时,nvidia_p2p_get_pages()注册的回调函数将总是被触发。内核驱动程序负责通过调用nvidia_p2p_free_page_table()来释放分配的page_table。需要注意的是,与桌面版本类似,该回调函数也会在取消固定回调中所述的情况下被触发。 -
由于
cudaHostAlloc()可以使用cudaHostAllocWriteCombined标志或默认标志进行分配,因此应用程序在将内存映射到用户空间时需要格外小心,例如使用标准的Linuxmmap()接口。在这方面:- 当以写组合的方式分配GPU内存时,用户空间映射也应以写组合方式进行,通过将
vm_area_struct的vm_page_prot成员传递给标准的Linux接口:``pgprot_writecombine()` 。 - 当以默认方式分配GPU内存时,不应对
vm_area_struct的vm_page_prot成员进行修改。
映射和分配属性的不兼容组合将导致未定义的行为。
- 当以写组合的方式分配GPU内存时,用户空间映射也应以写组合方式进行,通过将
评论