RDMA是如何成为高速网络引擎的?
两次偶然的邂逅使得远程直接内存访问(RDMA)从一个比较冷门的技术转变为了世界上最强大超级计算机的引擎。
这一幸运的机遇成就了以色列一家初创企业Melllanox的财富,该企业将赌注押在基于RDMA的InfiniBand网络上。
这一切始于2001年8月。俄亥俄州立大学的教授D.K. Panda与新资助的Mellanox的市场副总裁Kevin Deierling相遇。Panda解释了他实验室关于消息传递接口(MPI),以及其如何将低成本系统组装成高性能计算集群。
Panda的团队在2002年的Supercomputing会议上首次展示了开源软件MVAPICH,让MPI在Mellanox的芯片上运行。
将RDMA应用于一个巨大的Mac系统
这些演示引起了来自弗吉尼亚理工大学的计算机副教授Srinidhi Varadarajan的兴趣。
Varadarajan 立刻建立了一个由80个节点组成的低成本集群,供校园内的研究小组使用、研究,吸引他们强烈的兴趣。
作为对最新技术的狂热追随者,Varadarajan将目标对准了IBM的PowerPC 970,这是一款拥有领先的浮点性能的新一代2GHz CPU,支持高性能计算编译器。苹果也将推出基于这两个CPU的台式机Power Mac G5。
在得到大学和政府的资助后,Varadarajan下单了1100台Mac G5系统。Varadarajan希望用InfiniBand将这些Mac系统连接起来,想用IB技术获得高带宽和低延迟,因为高性能计算应用程序往往对延迟敏感。
RDMA推动10万亿次浮点运算
Varadarajan的系统性能测试在10万亿次浮点运算位稳定运行,这个价值520万美元的系统在2003年11月的超级计算机TOP500名单中排名第3。当时速度最快的系统是日本的地球模拟器,估计花费了3.5亿美元。
现在,TOP500上超过一半的系统使用带有RDMA的芯片,高性能计算是成为RDMA业务的重要组成部分。
RDMA于1993年11月诞生
1993年11月,RDMA首次在由一组惠普工程师在一项专利中明确提出。
像许多进步一样,RDMA背后的想法是简单而基础的。它提供一种网络系统访问彼此主内存的方法,而不会中断处理器或操作系统,从而降低延迟,提高吞吐量。
1999年,成立InfiniBand Architecture Specification(IBTA)。
2000年,发布了第一版的InfiniBand标准。
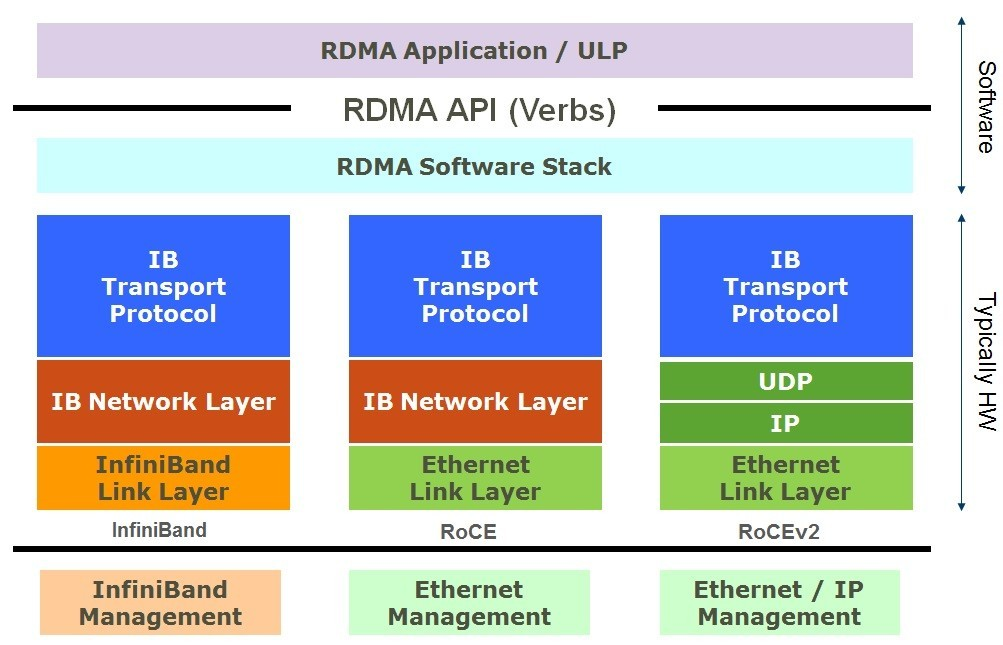
RoCE:RDMA成为主流
在RDMA组成的第一个超级计算机成功之后,RDMA逐步集成到成熟的以太网络中,但这付出了许多艰苦工作和时间。
2002年,在IB第一个版本发布两年后,成立RDMA联盟,作为IETF的补充。
2007年,提出基于TCP/IP的RDMA, iWARP。
2010年,InfiniBand Trade Association定义了RoCE v1(RDMA over Converged Ethernet,发音为“rocky”)
2014年,提出更完整的版本RoCE v2,并支持路由功能。
RDMA 智能网卡
现在,RDMA几乎无处不在。现在的智能网卡可以实现自适应路由、拥塞管理,而且越来越多地担当安全监控的角色。它们“实际上是在计算机前再放置一个计算机”,解放服务器CPU。
基于RDMA和RoCE构建的明天智能网络的下一个角色是加速不断增长的人工智能应用程序的发展。
RDMA 与 AI
AI和RDMA的结合使得Mellanox和NVIDIA走到了一起。
2019年3月,他们达成了价值69亿美元的合并协议,合并交易于2020年4月27日完成。
NVIDIA首次在其Kepler架构的GPU和CUDA 5.0软件中实现了RDMA,并通过GPUDirect Storage扩展了这一功能。
随着超级计算机采用了Mellanox基于RDMA的InfiniBand网络,它们也开始采用NVIDIA的GPU作为加速器。
评论