Nvidia 数据包喷洒技术、自适应路由技术实验验证
引言
数据包喷洒技术是一种保证网络链路均匀性的技术,它基于包或者cell进行负载均衡。
本文基于Nvidia Connect X6 DX网卡,开启网卡无序报文接收功能,使用支持乱序传输的RoCEv2 RC协议,对该技术进行实验验证。
什么导致数据包重排?
首先,让我们分析下生产环境中,可能出现的的重排场景,以及其发生的条件。
在数据包喷洒技术中,数据报文在leaf节点基于数据包逐个、随机选择传输路径,过程示意如下图所示。
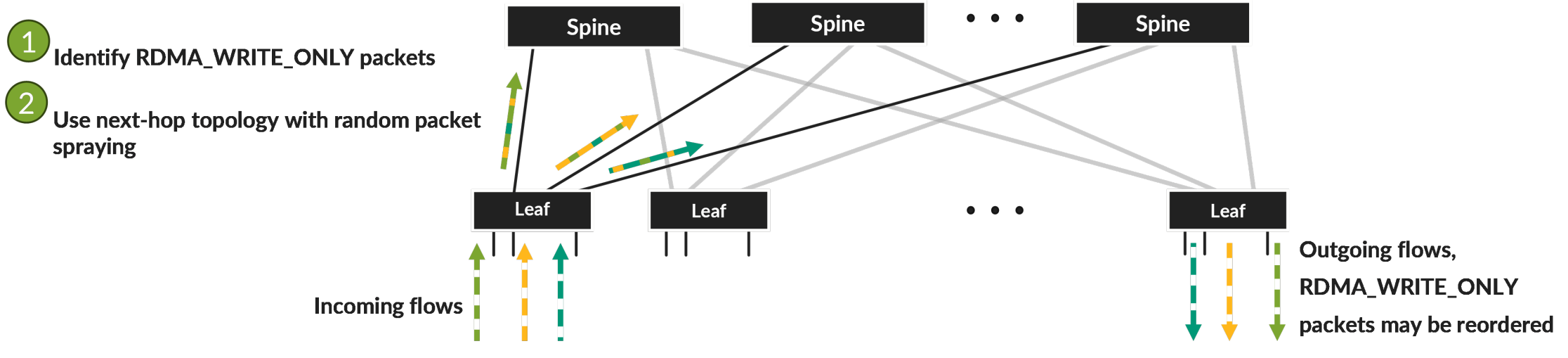
同一流量的数据包被定向到不同的队列中。由于各个队列中可能存在其他数据包,导致同一流的一些数据包在网络中排队时间较长,先发送的数据报文,可能更晚地到达终点,导致同流的数据报文乱序。
下图展示了一个例子:其中一个数据包因为spine端口队列中的其他数据包而延迟,最终导致流量中数据报文重排序。

自适应路由技术中,负载均衡是随机的,因此在更长时间内,系统中的所有路径都会均匀加载,但在非常短的时间(微秒级别)内,可能会有几个数据包偶然选择相同的路径。另外,同一个队列的数据包数量取决于输入和输出端口数量:
- 在叶子节点上,通常有16个或32个GPU端口向16个或32个上行端口发送流量。
- 在3级CLOS网络中,许多叶子节点(通常从32到64个)可能选择同一个spine设备,导致去往目标节点的链路拥塞。
这里主要关注: 较低序列号的数据包在较高序列号的数据包之后到达的情况。
在此测试中,首先验证数据包乱序到达时,相隔1至20个其他相同流的数据包的情况。
另外两项测试,则验证连续的乱序数据包之间相隔超过200和400个数据包的情况。
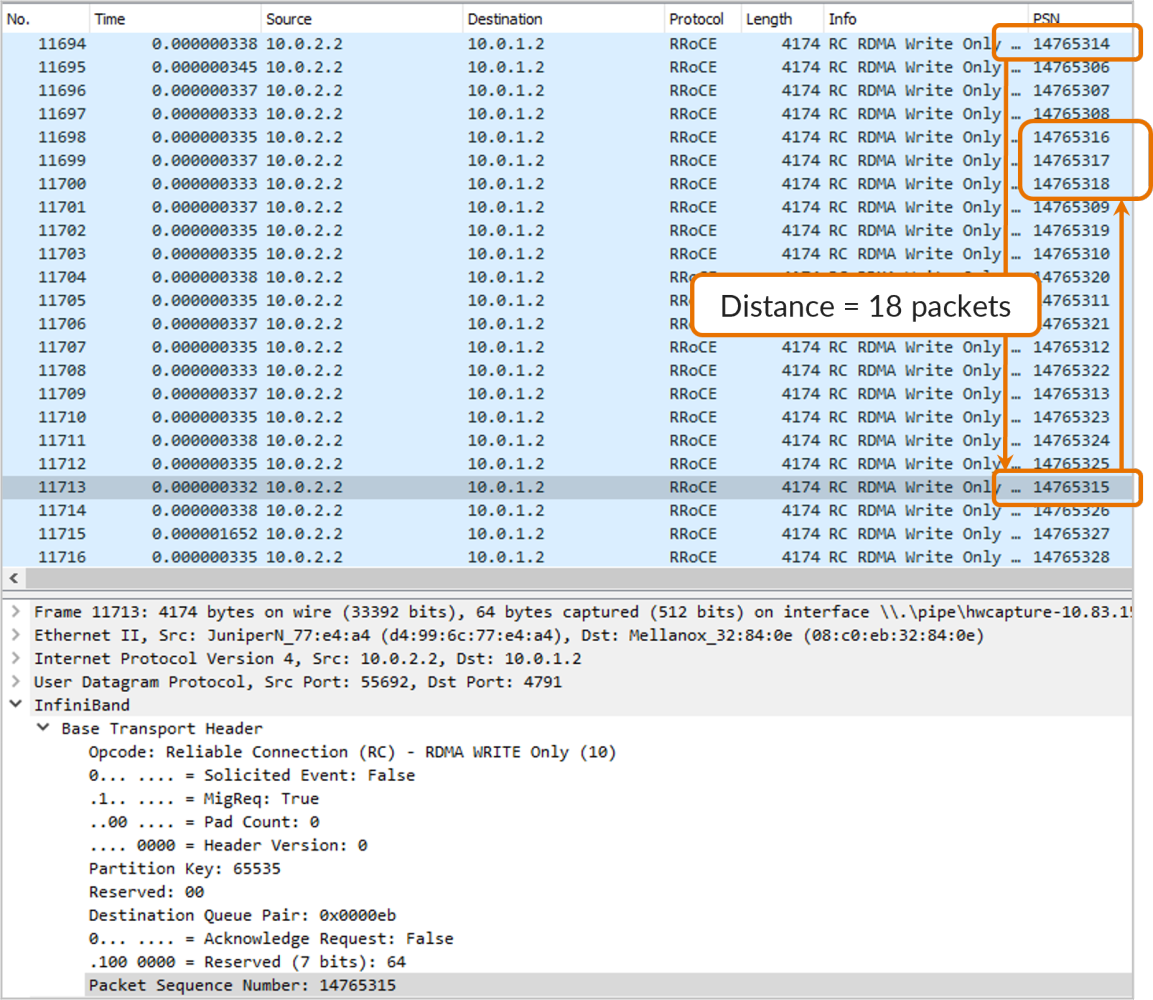
下图展示了两个连续的乱序数据包之间距离(以数据包数计)为18的情况。
注意,乱序数据包之间的距离是评估重排序情况的重要指标。下图显示了在测试中使用的数据包距离分布,以总数据包数量的百分比显示。

实验环境搭建
在此测试中,使用的路由器为Juniper Networks MX,通过配置路由器,使得25.03%的数据包以无序方式到达目标网卡。
下图展示了流量通过路由器的流向(从右至左)。
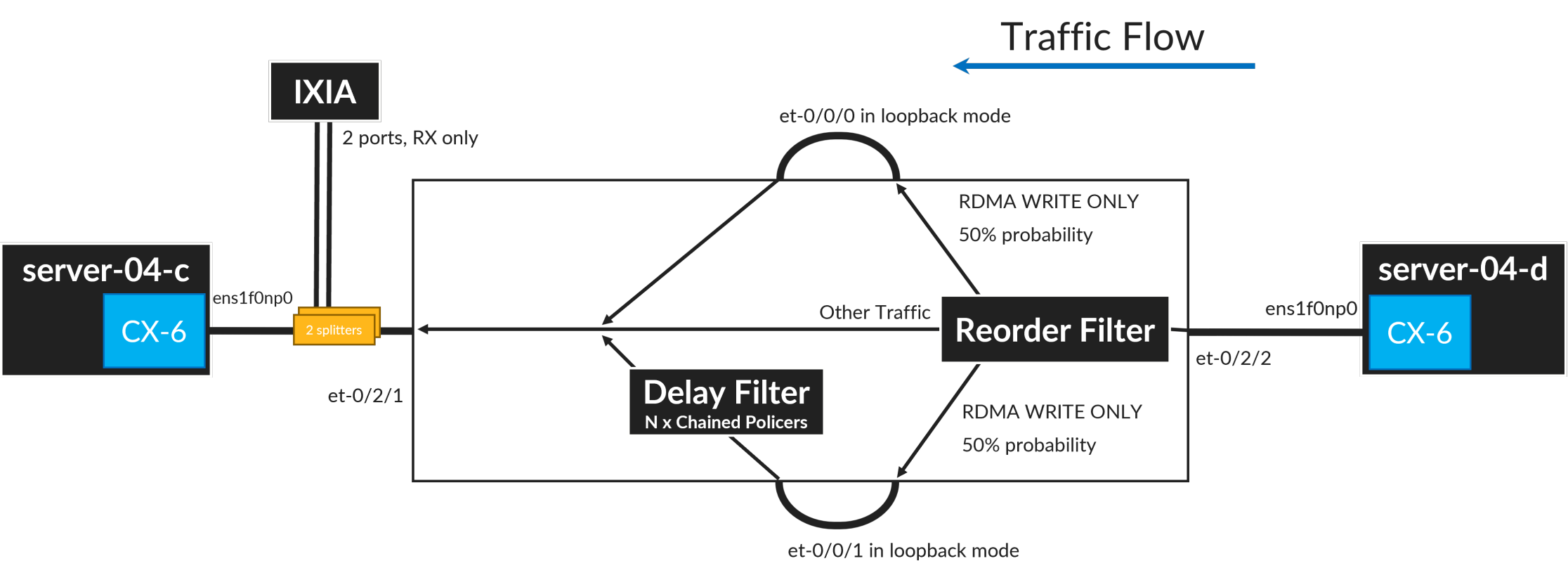
采用以下技术来模拟数据包重排:
- 将RDMA_WRITE_ONLY数据包分为两组:按照正常(短延迟)路径和按照较长路径的数据包,路径选择是随机的,概率相同为50%。其他非RDMA_WRITE_ONLY数据包通过第三条(直接)路径发送。
- 在其中一条路径上添加额外的延迟,通过在过滤器中链接8个策略指令实现,这样可以增加几微秒的数据包处理时间。为了避免丢包,选择非常高的策略器速率 - 策略器除了添加延迟外,对数据包处理没有影响。通过更改链中策略器的数量,可以控制距离分布。
本测试使用Nvidia Connect X 6 DX网卡(RoCEv2自适应路由功能要求固件版本高于或等于22),通过100GE接口连接到leaf交换机。
具体硬件如下:
- Connect X 6 DX网卡(型号MCX623106AC-CDA_Ax),固件版本22.38.1900。
- Supermicro服务器,配备Intel(R) Xeon(R) CPU E5-2670 v3 @ 2.30GHz,Ubuntu 22.04.3 LTS。
测试结果
本测试使用perftest包中的 ib_write_bw 进行测试。这里为了确保处理器和网卡位于同一个NUMA,进行了绑核处理。
以下是示例输出:
root@rtme-server04-d:/home/regress# taskset -c 12 ib_write_bw -d mlx5_0 -i 1 10.0.1.2 -F --perform_warm_up --report_gbits -D 600
-------------------------------------------------- --------------------
RDMA_Write BW测试
双端口:关闭 设备:mlx5_0
QP数目:1 传输类型:IB
连接类型:RC SRQ使用:关闭
PCIe放松顺序:开启
ibv_wr* API:开启
TX深度:128
CQ调节:1
MTU: 4096[B]
链路类型:以太网
GID索引:3
最大内联数据:0[B]
rdma_cm QPs: 关闭
数据交换方法:以太网
-------------------------------------------------- ------------
本地地址:LID 0000 QPN 0x0121 PSN 0xc97e49 RKey 0x202f00 VAddr 0x007ff87e05f000
GID:00:00:00:00:00:00:00:00:00:00:255:255:10:00:02:02
远程地址:LID 0000 QPN 0x011f PSN 0xf1eb2 RKey 0x202f00 VAddr 0x007f4dcc873000
GID:00:00:00:00:00:00:00:00:00:00:255:255:10:00:01:02
-------------------------------------------------- ------------
#字节 #迭代 BW peak[Gb/sec] 平均带宽[Gb/sec] MsgRate[Mpps]
65536 55881440 0.00 97.66 0.186272
-------------------------------------------------- ---------------
首先,我们在3种不同的场景下进行了测试,每个场景运行10分钟,最终得到与理论最大性能相匹配的结果:
- 自适应路由:启用。Spraying:禁用。吞吐量:97.66 Gbps。
- 自适应路由:启用。Spraying:启用。吞吐量:97.66 Gbps。
- 自适应路由:禁用。Spraying:禁用。吞吐量:98.01 Gbps。
对于携带4096字节有效负载的数据包,L2和L3开销为78字节,L1添加了20字节的开销。4096 / 4194 * 100Gbps= 97.66332 Gbps。
请注意,如果禁用网卡的自适应路由选项,网络开销会稍微减少(性能降低了0.34%),因为网卡自适应路由选项让每个数据包都有RDMA Extended Transport Header (RETH)。
下面测试禁用网卡自适应路由选项时,分组重新排序的对性能的影响。在这个测试中,经过MX路由器的所有数据包都进行了重新排序。
正如预期的那样,性能下降了80倍以上(可能是因为数据包之间的间隔增加而导致无法观察到重新排序),影响巨大。
- 自适应路由:禁用。数据包喷洒:启用。吞吐量:0.19 Gbps。
可见,数据报文喷洒只有在端点支持无序数据包接收的情况下才能进行。
最后,又进行了两次测试,以测试网卡能够承受多少重新排序(在默认网卡配置下)。在第一个测试中,路径数量增加到8个,并使用以下策略/计数器组合来调整延迟(更多的策略/计数器指令会增加延迟):
- 路径1:0个策略/计数器
- 路径2:8个策略/计数器
- 路径3:8个策略/计数器
- 路径4:8个策略/计数器
- 路径5:16个策略/计数器
- 路径6:32个策略/计数器
- 路径7:64个策略/计数器
- 路径8:128个策略/计数器
下图显示了生成的距离分布。
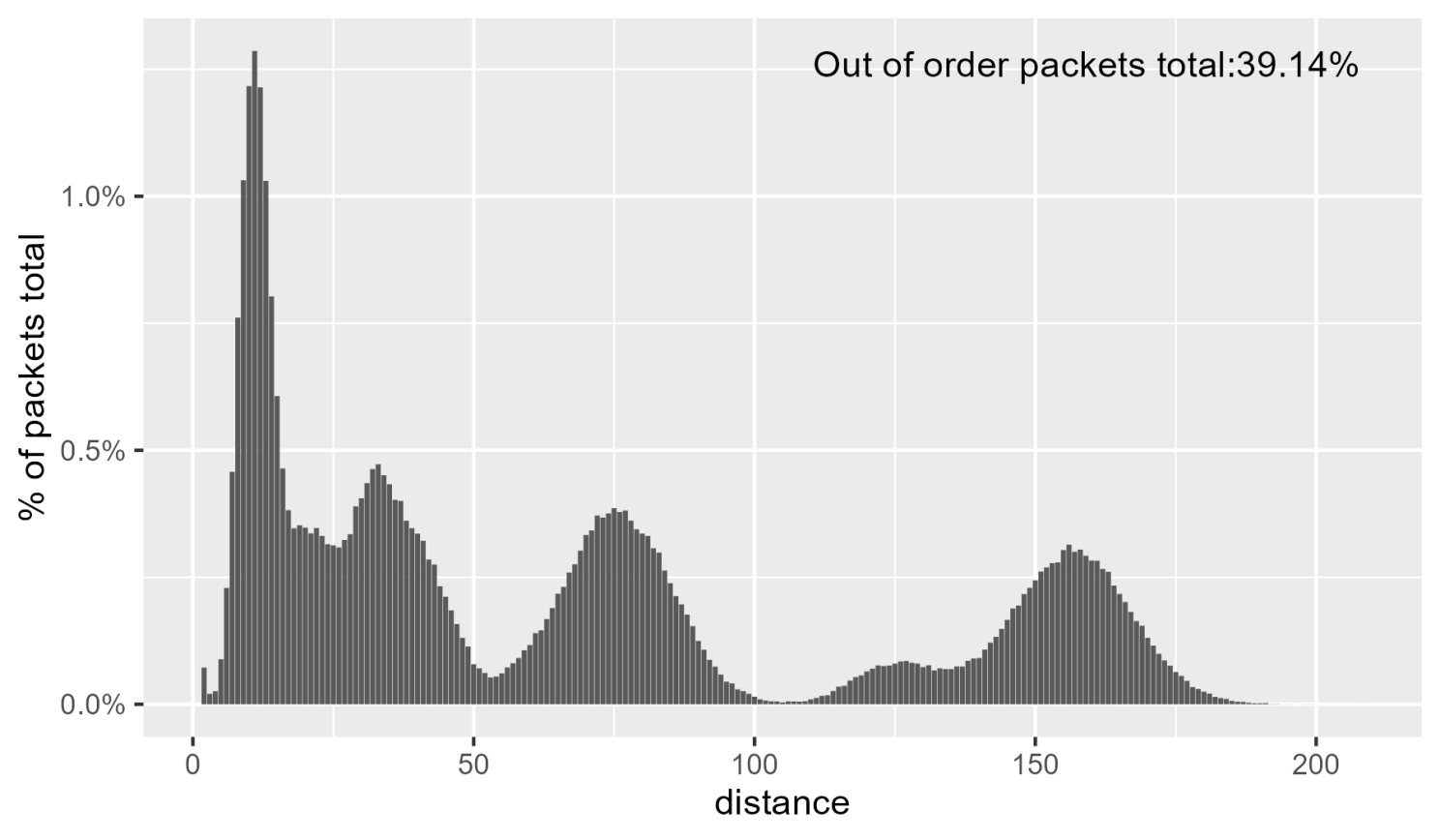
最后一次测试将路径2的策略/计数器数量从8增加到256,最大距离进一步增加,如下图所示。
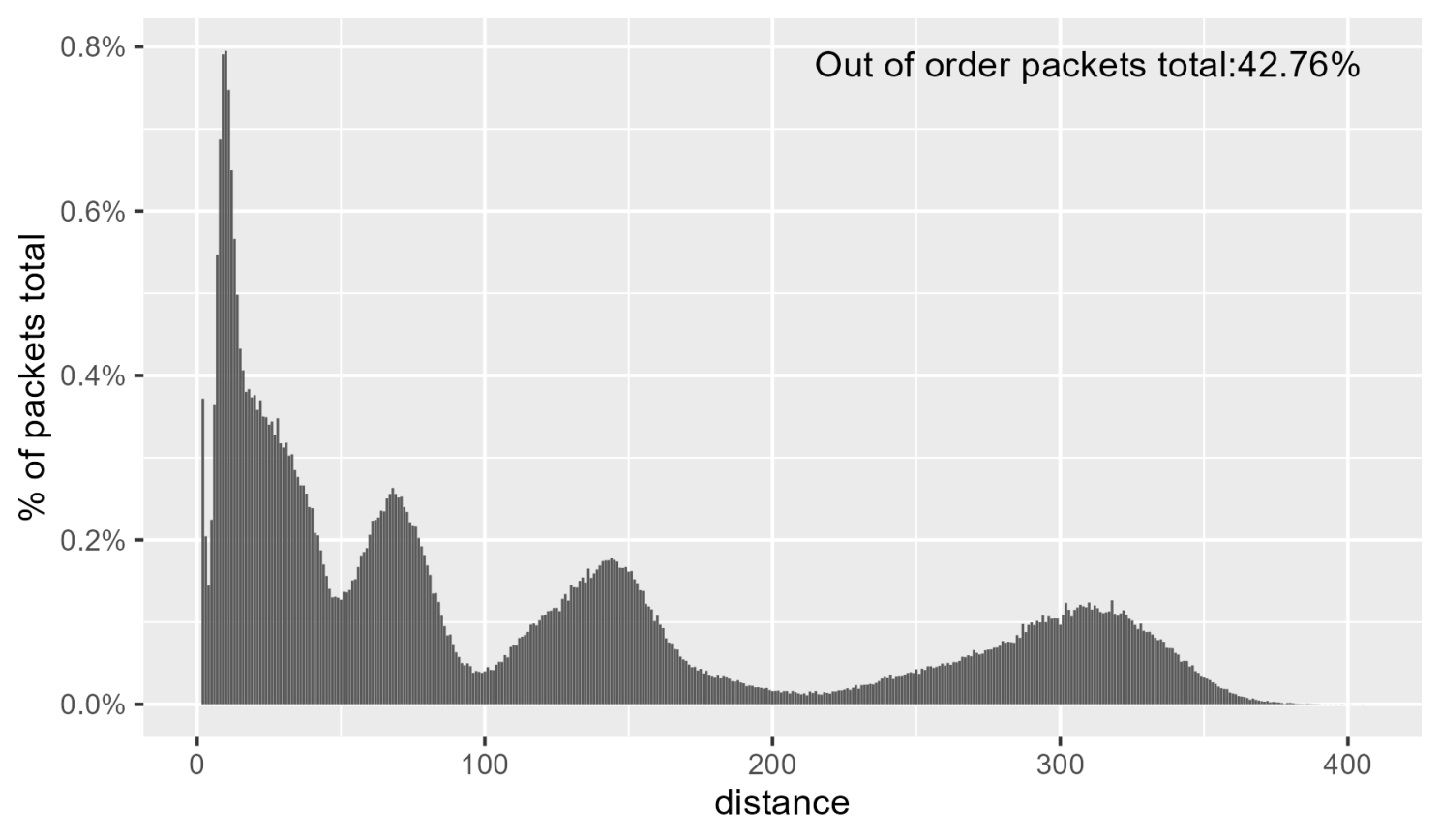
性能结果如下所示:
- 距离为200+的配置。自适应路由:启用。数据包喷洒:启用。吞吐量:97.66 Gbps。
- 距离为400+的配置。自适应路由:启用。数据包喷洒:启用。吞吐量:87.58 Gbps。
从测试结果可以看出,在具有非常大的重新排序的情况下,性能可能会下降。请注意,没有发现丢包,并且很可能当未确认的数据包数量达到配置/支持的最大值时,速率会降低。
总的来说,自适应路由和喷洒的组合效果非常好!
但是这样做的代价是什么?
这样做的代价是什么?
如果网卡启用了无序数据包接收(自适应路由),那么带确认的数据包数量会增加,这会带来吞吐量降低0.34%。
在非自适应路由的情况下,确认消息是针对整个数据产生的(可能由RDMA写首部、RDMA写尾部和多个RDMA写中间数据包组成)。
而在自适应路由的情况下,确认是针对一组由3至4个RDMA写数据包组成的数据包组合生成的。
下面是带确认的数据包的抓包截图。
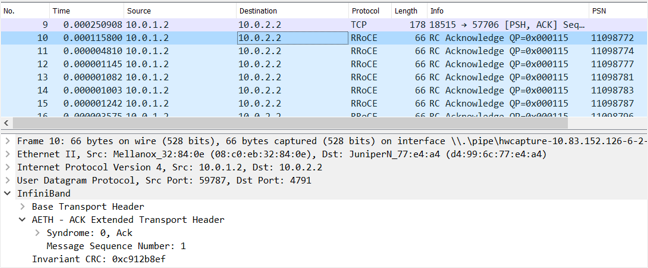
对于发送方向上的3至4个的数据包(每个4K字节),接受方发送一个小的66字节的L2数据包。与其他技术(如完全调度的网络)相比,对于传输12K到16K的数据来说,66字节不是很大的开销,占比0.4%-0.5%。
结论
可见,开启数据包喷洒技术与网卡无序数据报文接收,可高效的对网络流量进行负载均衡,避免拥塞,从而减少作业完成时间。
参考
- https://github.com/NVIDIA/nccl/tree/master/src
- https://people.eecs.berkeley.edu/~apanda/assets/papers/sigcomm18-irn.pdf
- https://enterprise-support.nvidia.com/s/article/How-To-Configure-Adaptive-Routing-and-Self-Healing-Networking-New
- https://mellanox.my.site.com/mellanoxcommunity/s/article/How-to-Enable-Disable-Lossy-RoCE-Accelerations
- https://docs.nvidia.com/deeplearning/nccl/user-guide/docs/env.html#nccl-ib-adaptive-routing
- https://www.linkedin.com/pulse/spray-solving-low-entropy-problem-aiml-training-fabrics-shokarev/
- https://www.linkedin.com/pulse/spray-validation-dmitry-shokarev
- https://support.huawei.com/hedex/hdx.do?docid=EDOC1100302093&id=EN-US_CONCEPT_0000001149739304
- mellanox自适应路由配置
- Adaptive Routing in AI/ML Workloads-youtube
附录
CX6 开启自适应路由
NVIDIA(原Mellanox)ConnectX-6 DX 网络接口卡(NIC)支持诸多先进特性,包括自适应路由(Adaptive Routing)。自适应路由是一种网络技术,可在InfiniBand网络中智能地选择数据包的路径,以优化网络流量并减少拥塞。这种技术可以根据网络条件动态调整路由,以提高性能和带宽利用率。
请注意,开启自适应路由功能通常需要对硬件配置、驱动程序和网络管理软件进行一定的设置。以下是一般步骤,但请根据您的具体设备和软件版本查看官方文档以获得最准确的指导:
-
确保NIC固件是最新的,且支持自适应路由特性。
-
安装NVIDIA提供的最新Mellanox OFED驱动程序。
-
使用适当的网络管理软件(可能是NVIDIA的UMA或OpenSM等)配置您的InfiniBand子网。
在InfiniBand网络中,通常是子网管理器(Subnet Manager,SM)负责配置网络上的路由策略。因此,自适应路由需要在SM层面进行配置。例如,使用OpenSM,你可以通过修改配置文件来启用自适应路由。
以下是一个例子:
opensm -o /etc/opensm/opensm.conf
在opensm.conf文件中,找到和修改或添加以下行以启用自适应路由:
routing_engine adaptive
保存文件并重新启动OpenSM服务以应用更改。
如果你使用的是NVIDIA的UMA,操作会有所不同,具体步骤应在它的用户手册中找到。
- 在NIC层面,可能还需要配置相关参数以适应自适应路由。这可以通过
ethtool或mlxconfig等工具来完成。
请记住,这些仅仅是一般性的指导步骤。实际操作时,一定要参考NVIDIA的官方文档,因为详细的步骤和命令可能会根据您的具体设备和软件版本有所不同。
如果需要进一步的技术支持,请联系NVIDIA的技术支持团队或参阅其在线资源,如用户手册、技术论坛和常见问题解答。
评论